Detection of Encrypted Cryptomining Malware Connections With Machine and Deep Learning
使用机器学习与深度学习对恶意加密货币挖矿软件加密连接的检测
简介:
如今,恶意软件已成为一个流行问题。在利用受害者计算机资源的攻击中,一种常见的攻击与数字货币加密所需的大量计算资源有关。网络犯罪分子从受害者那里窃取计算机资源,将这些资源与他们从中受益的加密货币矿池相关联。这项研究工作的重点是提供一种解决方案,仅通过被动网络监控来检测此类滥用的加密货币挖矿活动。为此,我们确定了一组新的高度相关的网络流特征,与一组丰富的机器和深度学习模型联合使用,用于实时加密挖掘流检测。我们为训练和测试机器和深度学习模型部署了一个复杂而真实的加密挖掘场景,其中客户端与互联网上的真实服务器交互并使用加密连接。进行了一组完整的实验以证明,将这些信息量丰富的特征与复杂的机器学习模型相结合,即使流量被加密,也可以在线路上以电信级的精度和准确度检测到加密攻击。
索引术语: 加密挖矿检测、恶意软件检测、加密劫持检测、加密货币挖掘、网络流量测量、加密流量分类、机器学习、深度学习。
一、引言
恶意软件是基于一个简单概念的流行问题:利用受害者的计算机资源。纵观最近的历史,恶意软件的演变提供了更大的弹性和多功能性来实现多个目标:拒绝服务 (DoS)、敏感数据盗窃、他人之间非法活动的匿名性。但总的来说,主要动机是经济。恶意软件家族开发了各种各样的技术来获利,从简单的 DoS 威胁勒索到复杂的银行木马,期望最终获得一些信托资金。在这种不可阻挡的演变 [1] 中,网络犯罪分子寻找新模式以获取快速利润。数字货币非常适合这种策略。
比特币 [2] 是第一个基于区块链的去中心化数字货币。任何拥有足够计算能力的人都可以参与并获利,进行加密计算来为区块链做出贡献。作为这种计算的结果,使用完全相同的加密货币提供了可变奖励。这通常被称为加密挖掘。不幸的是,独立的加密货币挖矿不再有利可图,解决方案是使用称为挖矿池的新型服务关联多台计算机(或机器人)。这些安排提供了与参与者使用特定协议提供的计算资源成比例的挖矿奖励的百分比(参见第 III 节)。如今,多种加密货币已经诞生和消亡[3],为挖矿提供了多种有利可图的生态系统。确切地说,作为这种生态系统扩散的一部分,一些加密货币产生了对专用硬件 (ASIC) 设备的反对,改变了算法 [4]、[5] 使它们变得无用,并再次打开了通过正常计算机挖掘获利的机会。
网络犯罪分子可以通过两种主要方法填充他们的加密货币钱包。 首先,通过利用勒索软件恶意软件家族来加密受害者的数据并使用无法追踪的加密货币接收付款,以便让受害者恢复加密信息。 第二种选择包括使用僵尸网络或在浏览器中执行非法进程(加密劫持),在未经受害者同意的情况下,将受害者的计算机资源秘密添加到抗 ASIC 的矿池中,并为犯罪分子的利益花费计算资源。 第一个具有引起当局关注的内在风险,取决于受害者的支付意愿,但也带来了准时的大好处。 相反,第二种方法可以长时间运行,产生不断增加的收益 [6]。
我们研究的重点是第二种方法,它为行业提供了一种检测网络上的加密挖矿活动的解决方案。 挖矿流量通常被加密以避免检测,僵尸网络可以使用私有代理 IP 来聚合和伪装挖矿池。
众所周知,如今越来越多的流量被加密(> 80%),因为许多网络协议(例如 TLS、SSH、QUIC、VPN)都采用了加密。此外,关注隐私问题的政府正在对电信提供商访问用户数据或检查数据包有效载荷施加限制。在这种情况下,我们提出了一种新的方法来检测网络上的加密挖掘活动(图 1),即使它是加密的,基于通过机器和深度学习技术分析挖掘客户端的网络行为,而不是经典的深度数据包和有效载荷检查技术或矿池域名识别。我们建议应用受监督的机器和深度学习技术,这些技术将排除使用 IP 地址、端口号或应用程序级别信息等可能包含个人和敏感用户数据的输入特征。此外,在机器学习模型的训练和测试阶段,加密流量将被广泛使用,因为这种类型的流量将在不久的将来变得普遍。

图 1. 分析网络行为以检测隐藏活动
由于多种原因,我们选择门罗币(XMR)作为本研究的加密货币挖矿协议。首先,Monero 是迄今为止地下市场网络犯罪分子最喜欢的加密货币 [6]。其次,Monero 开发人员公开承诺将 ASIC 排除在挖矿生态系统之外,并且所需的资源量很少(例如 RandomX 算法 [5] 中的轻型模式,只需要 256 MiB 的共享内存),增加了恶意软件对其的采用家庭。最后,门罗币对 CPU 挖掘的偏好使得在 GPU 或 ASIC 设备方面对标准客户端的实验更加现实。我们在一个受控但现实的环境中证明,仔细的特征选择对于在存在加密货币流的交通场景中使用机器和深度学习模型获得良好的检测性能至关重要。我们使用从网络流量低点获得的两组不同的统计特征来比较机器学习性能。第一组是使用 Tstat 工具提取的,这是一种众所周知的被动嗅探器,能够在网络和传输级别提供每个流的统计信息,第二组来自 IETF 标准 NetFlow/IPFIX 指标,这些指标在行业中广泛使用.据我们所知,我们的研究工作是第一个利用 Tstat 获得的特征作为监督机器学习算法的输入的提议。我们证明了第一组比第二组提供了更多的信息,这意味着,独立于所使用的机器学习模型,预测更稳定、准确和精确。此外,我们表明复杂模型(例如随机森林和完全连接的深度神经网络)能够以比简单模型(例如决策树和逻辑回归)显着更高的精度、准确度和稳定性来检测加密流量活动,即使流量是加密。最后,我们得出结论,如本文中提出的那样,复杂的机器学习模型使用 Tstat 获得的一组详尽特征作为输入,以工业部署所需的准确度、精确度和稳定性识别加密货币流量。
二、贡献
通过网络检测加密挖掘恶意软件仍处于起步阶段,据我们所知,只有一项研究工作 [7] 解决了这个问题,但假设了一个相当不切实际的场景,其中 i) 不考虑加密流量, ii) 只提出了一组简化的传统机器学习模型,并且 iii) 一组稍微没有信息的特征被用作输入。因此,当在我们的受控环境中重现实验时,获得的性能与电信行业的预期相差甚远。为了超越当前提案的局限性,我们的实验工作提出了以下新颖性:
-
一个复杂而真实的挖矿场景,用于训练和测试用于挖矿流检测的机器学习模型。该场景由典型的 Internet 应用程序(例如 Web 浏览、多媒体、通过共享文件夹访问文件)和与分布在 Internet 上的真实挖矿服务器池交互的加密客户端组成。这种受控设置允许生成真实的网络流量,即使流量被加密,也可以 100% 的精度自动收集和标记。标记的流量将用于训练和测试机器学习模型,用于满足电信行业严格要求的加密货币流检测。我们的实验设置与现有作品的一个显着特征是除了非加密连接之外还使用加密连接。如今,越来越多的应用程序对其通信进行加密,其内容的识别对机器学习分类器,尤其是密码挖掘检测器提出了额外的挑战。
-
提议将一组新的信息丰富的特征用作实时密码挖掘流检测的输入。这些功能源自 Tstat 生成的一组取证统计数据,该工具旨在从网络数据包跟踪中生成每个连接的统计数据。我们修改了 Tstat 工具以导出一组实时流特征,以输入到 ML 分类器以进行密码挖掘检测。在我们的实验中,我们证明了当网络流量被加密时,与使用标准特征相比,使用提议的新特征集显着提高了 ML 性能。
-
一套完整的实验表明,即使流量被加密,也可以使用派生的 Tstat 特征和复杂的机器学习模型,以电信级的精度和准确度在线路上检测到加密攻击
三、加密货币和加密挖掘协议
加密货币可以定义为数字交换媒体,基于使用加密原语来规范新加密货币单位的发行和验证交易。中本聪 [2] 在开创性论文中介绍了第一个也是最广泛使用的加密货币比特币 (BTC)。加密货币是完全去中心化的,没有控制权,这是 P2P 文件共享网络的共同特征。交易的验证基于分布式账本,通过区块链(一种不可变的共享数据结构 [8])实现。当使用加密货币时,相关交易被添加到区块链中。然后,加密货币用户(称为矿工)可以通过计算密集型加密过程(通常称为挖矿)验证新区块,即一组交易,以防止不公平地使用加密货币(例如双重支出)。鼓励矿工通过奖励(即新的加密货币单位)参与交易验证。然而,验证过程的高度复杂性使得获得此类奖励仅适用于专用硬件 (ASIC) 所有者。矿池试图克服这一限制,协调不同矿工的工作和资源,他们通过网络共享计算能力。用于在矿池参与者之间分配挖矿过程的最广泛协议称为 Stratum [9],并且已首先用于 Slushpool 矿池 [10]。
图 2 所示的 Stratum 协议指定了矿池服务器与其参与者之间的双向通信通道,消息编码遵循 JSON-RPC 2.0 规范 [11]。下面,我们将简要描述典型的 Stratum 协议流程。首先,客户端可以发起(或恢复)与矿池服务器的会话,调用服务器上的订阅RPC方法,在请求中指定客户端将使用的挖矿软件来解决服务器随后将发送给的挑战客户端。需要注意的是,一个矿池用户在挖矿过程中可能会使用多个设备(Stratum 术语中的 Worker)。因此,客户端还需要授权服务器向每个工人发送挑战,通过为每个工人调用服务器上的授权 RPC 方法,将其用户名和密码发送到服务器(图 2 中的步骤 1)。然后,服务器可以向工作人员发送挑战,向他们调用提交 RPC 方法(图 2 中的步骤 2)。如果工作人员找到了挖矿挑战的解决方案,他可以通过调用提交 RPC 方法将其发送到服务器(图 2 中的步骤 3)。在验证解决方案的正确性后,服务器可以向解决挑战的工作人员以及其他试图解决问题的工作人员发送新的挑战,再次调用他们的提交 RPC 方法。 Stratum 消息可以以加密形式发送,例如将它们嵌入到 TLS 帧中 [12]。
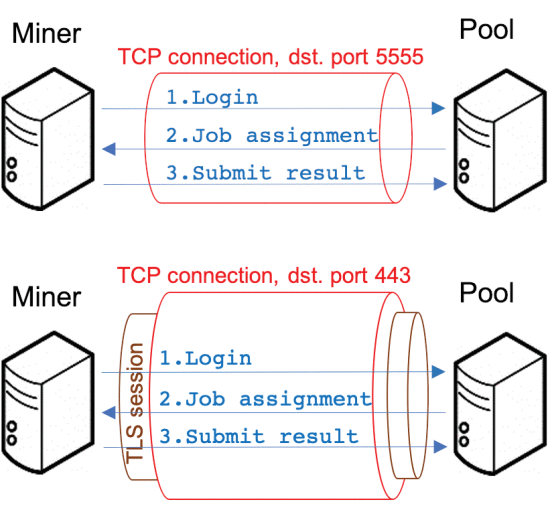
图 2. Stratum协议涉及的消息流。上图在TCP连接中运行,通过TLS会话的Botton图
四、 相关工作
尽管是当今工业场景中的热门话题,但在当前的科学文献中,对加密采矿活动的检测却鲜有研究。 大多数当前最先进的工作主要集中在通过分析目标节点的行为来检测在受害者身上运行的加密挖掘或加密劫持软件模块。 尝试检测 Stratum 或其他加密挖矿协议的作品更少。
A. 加密流量的识别
很少有研究工作专注于通过查看网络流量来检测密码挖掘活动。与我们的研究最接近的工作是由 Muñoz 等人提出的。在 [7]。在这项工作中,作者评估了四种不同的机器学习技术(SVM、朴素贝叶斯、CART 和 C4.5 决策树),以识别应用非 DPI(深度数据包检测)方法的非加密加密矿层流。他们得出的结论是,可以识别用于挖掘五种不同加密货币(比特币、比特币现金、DogeCoin、莱特币和门罗币)的非加密 Stratum 连接。此外,作者表明,一些机器学习模型(例如 CART 决策树)能够准确地区分这些加密货币挖掘流与正常流量,并对正在挖掘的加密货币进行分类。我们研究与这项工作的主要区别在于(a)我们提出了更复杂的模型(随机森林和完全连接的神经网络)来检测加密活动,这显着提高了预测的稳定性、精度和准确性,(b)与 Muñoz 等人的方法相比,我们的研究中还考虑了加密流量,以评估现实场景中的机器学习性能,并且 © 我们使用了由 Tstat 工具派生的 51 个特征的更多信息集,这些特征产生了明显更好的效果结果比 Muñoz 等人采用的方法要好。仅利用来自 NetFlow/IPFIX 指标的 8 个功能。在我们设置的现实场景中比较这两个提议的结果,可以观察到,使用具有 Netflow 特征的更简单的机器学习算法,如 [7],在机器学习预测中会产生不稳定和较差的性能。另一方面,当复杂的机器学习模型与更多信息特征结合使用时,如我们工作中提出的那样,可以获得高性能、稳健和稳定的预测。
斯威丹等人。 [13] 提出了一组更传统的方法来检测并最终阻止加密挖掘连接。 作者提出了一种名为 MDPS(挖矿检测和预防系统)的架构,用于丢弃由浏览器(例如 CoinHive、Crypto-Loot)生成的非加密挖矿流。 他们的方法基于部署代理,对连接执行 DPI 检查以拒绝任何可疑流量,当矿工加密他们的通信时,这是相当无效的。
B. 加密软件模块的识别
检测加密挖矿进程的大部分工作都使用安装在主机上(通常在浏览器内)的某种监控代理,该代理持续监控系统资源,并在检测到一些奇怪的行为时做出反应。
在 Konoth 等人的工作中。 [14],作者提出了一种方法,能够通过静态分析网页中的 WebAssembly 代码来检测浏览器内的加密活动。密码挖掘基于计算多个散列值,并且这些函数具有特殊的模式(例如,长序列的 XOR 指令或使用各种加密原语函数),可以通过分析汇编操作码找到这些模式。作者提出了 MineSweeper,该组件可以分析网页加载的所有 WebAssembly 指令,并在模式分析显示加载了潜在的加密矿工时做出相应反应。代码的分析不是由机器学习技术执行的,但作者手动调查了最常见的浏览器中的矿工,并在他们的工具中硬编码了他们的模式。
卡林等人。 [15] 使用动态方法来检测浏览器中的加密矿工。他们的方法利用通过调试器 (OllyDbg) 启动浏览器 (FireFox) 收集的跟踪(发送到 CPU 的指令列表)。然后对这些跟踪中指令的操作码进行计数,然后将此整数向量用作随机森林分类器的输入特征。他们的机器学习模型经过训练能够区分:加密脚本、停用的加密脚本(没有开始挖掘函数调用的文件)、规范脚本(不是与加密相关的文件)和规范注入脚本(规范脚本的武器化版本,但注入了一些加密挖掘脚本)。他们的方法能够在每个类别上获得近 100% 的准确率。
刘等人。 [16] 修改了 Chrome 浏览器的内核,以包含名为 BMDetector 的矿工检测组件。该组件分析浏览器的堆内存和堆栈跟踪,并将它们发送到 LSTM(长短期内存)循环神经网络,该网络执行两类的实际分类:挖掘和非挖掘脚本。
Kharraz 等人也考虑了其他机器学习模型。 [17] 通过分析浏览器行为来识别加密劫持网站。他们的监控代理 Outguard 不断检查浏览器加载和执行的脚本,计算简单的数字特征并将它们发送到经过训练的机器学习模型以检测加密脚本。它们的功能包括脚本使用了多少并行任务、是否请求了 WebAssembly 或创建了多少 WebSocket。他们测试了随机森林和 SVM(支持向量机),并通过实验发现 SVM 获得了最好的结果。
五、问题设定
受害者通常不会将此类攻击视为问题,主要是因为没有直接的经济损失或赎金。识别加密货币开采时产生的流量(在所谓的加密挖掘过程中)对公司和最终用户都有用。首先,公司可能有兴趣检测在其公司网络上交换的层加密信息,因为他们可以指出一个或多个员工正在使用公司资源(例如公司拥有的设备、电力)来挖掘加密货币,从而获得非法经济收益损害公司财务。第二种情况是关于加密劫持的令人担忧的威胁,它危及最终用户和公司。网络犯罪分子正在了解加密挖掘的经济潜力,因此,他们传播恶意软件,在成功感染目标设备后,隐藏在受害者设备上运行的加密挖掘过程。加密挖掘,尤其是在不受限制的情况下,可能对最终用户设备的性能、移动设备的电池持续时间极为不利,并可能导致此类设备的使用寿命缩短。此外,加密劫持相关流量的识别可用作受监控设备的入侵指标 (IoC),即使负责的恶意软件尚未包含在反恶意软件应用程序数据库中。
因此,基于网络流量分析检测和阻止加密挖矿活动可以消除以前对 IT 资源的影响,并阻止使用非法加密通信。首先,因为无法进行通信,挖矿过程停止消耗资源。其次,因为如果无法使用网络订购或收集计算交易,则不会产生奖励。
为了准确和精确地检测网络上不同类型的挖矿活动,我们提出了一个受控的网络环境,使用真实的客户端和服务器来生成与正常流量(网上冲浪、视频和音频流、云存储、文件传输、电子邮件和 P2P 等)通过专用网络并通过住宅宽带接入共享互联网连接。正常流量客户端与位于专用网络和 Internet 中的服务器交互。 Cryptomining 客户端连接到 Internet 中的真实矿池。作为迄今为止网络犯罪分子最喜欢的加密货币,门罗币被选为我们实验的加密货币。选择了两个不同的 Monero 客户端来提供 Stratum 协议的实现多样性,这是迄今为止最广泛用于在矿池之间分配挖矿过程的协议。客户端虚拟机中的 CPU 和内存在普通用户计算机的范围内分配,没有任何专用硬件(如 GPU 或 ASIC)的支持,并且相同的约束应用于服务器虚拟机配置。我们为所有客户端和服务器配置了建立普通或加密连接的能力。特别是,加密客户端连接到支持两种类型的网络连接的矿池。
最后,我们提供了通过物理交换机中的端口镜像功能来捕获和复制穿越受控网络环境的所有网络流量的能力。通过这种方式,所有捕获的流量都可以被标记和存储以用于训练有监督的机器学习模型或直接用于测试目的。收集的数据包使用众所周知的 5 元组分组为流:IP 目标、IP 源、端口目标、端口源和传输协议。在机器学习模型的训练阶段,每次新数据包到达时,都会生成一组流统计信息(特征)并与数据集中的相应标签一起存储,用于训练或测试目的。在生产环境中,特征从流中提取并输入到先前训练的机器学习模型中,以概率值的形式预测流类型(例如加密或正常流)。
六、机器学习模型
为了找到性能最佳的模型,我们考虑了不同的监督机器和深度学习分类器,以利用它们各自的特定特征。鉴于我们不假设要输入到模型的特征之间的时间或空间关系,我们决定使用基于全连接神经网络 (FCNN) 的深度学习架构。此外,我们还考虑了其他几种著名的机器学习算法,例如逻辑回归模型 [18]、[19]、分类和回归决策树(CART [20] 和 C4.5 [21])和随机森林 [22] ]。
Logistic 回归模型本质上是一种分类算法,它允许对仅具有两个可能值之一的二元结果进行建模。有几项工作建议将该技术应用于基于协议的 Internet 流量分类([23]、[24])。
分类和回归树 (CART) [20] 和 C4.5 算法 [21] 是决策树模型,能够根据从离散和连续特征推断出的规则树将数据分类为不同的类别。这些模型允许根据树的结果叶子的概率对输入特征向量进行分类,给出属于特定类别的概率。
随机森林 (RF) 模型 [22] 结合了几个决策树(特别是 CART 树),通过引导程序聚合(装袋)和每棵树的随机选择特征,使用多数投票过程产生更准确的分类。 RF 模型因其非线性分类能力、效率和鲁棒性而被广泛使用([25]、[26])。
全连接神经网络 (FCNN) 模型 [27]、[28],也称为多层感知器,是一种前馈神经网络,它将节点组织成层,加权连接从一层到下一层前馈。输入向量从输入层通过隐藏层向输出层传播,以便将输入映射到输出向量。 FCNN 模型已成功用于从大量数据中识别复杂模式的广泛问题和领域。特别是在 [29] 中,它被用来检测网络流量上的 DDoS 攻击。
七、 我们的方法
我们的目标是将加密挖矿流量与常规互联网流量区分开来,后者是由网络连接、电子邮件传输、流媒体视频、云服务之间的数据传输等组成的各种流。 为了实现这一目标,我们使用图 3 中描述的工作流程来生成合适的数据集并训练一组机器和深度学习模型。
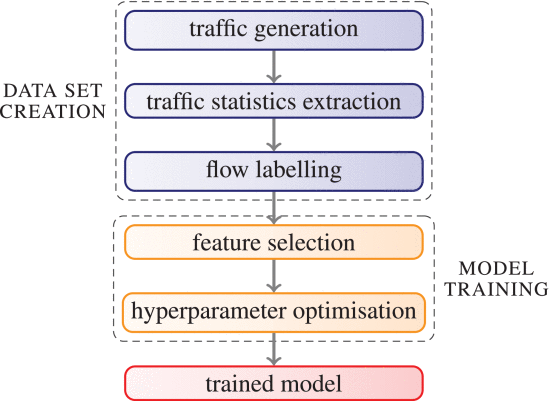
图 3. 我们的训练工作流。
任何基于机器学习的过程的第一步都是生成高质量的数据集。我们使用 Mouseworld [30],一个基于 NFV 的受控基础设施,在其上设置和部署加密攻击场景,该场景将产生我们的实验流量。我们安装了一系列虚拟机,一些矿工连接到互联网来产生加密和非加密的 Stratum 流,并使用各种其他方法来收集常规流量
(例如 HTTP/HTTPS 流、多媒体流)。 TCP 流由流量分析工具 Tstat 的修改版本捕获和分析,以便实时提取从多个连接统计数据中提取的一组特征,这些特征用作我们机器学习模型的输入特征。然后,我们在一个名为 Tagger 的特殊 Mouseworld 内部组件中添加了一个临时代码,以自动为每个 TCP 流实例分配一个二进制标签(0:正常流量连接,1:加密连接)。被标记后,我们使用这些样本来训练和测试各种机器学习模型。然而,在实际模型训练之前,我们执行特征选择阶段以提高模型的准确性,并执行超参数优化步骤以搜索最佳模型配置。为了验证我们的模型的质量,我们使用了与图 3 中描述的方法类似的方法,通过使用 Mouseworld 作为我们的网络基础设施,以便根据需要多次生成各种新的和现实的流量样本,以进行分类我们的机器学习模型。值得注意的是,ML 模型训练是在单独的环境中完成的,在该环境中,可以使用专门的 GPU 卡来加速深度神经网络的训练过程。
以下段落更详细地描述了我们如何构建数据集以及我们如何训练我们的模型,而第 VIII 节包含我们的实验结果。
A. 数据集创建
如前所述,我们网络基础设施的基础是 Mouseworld 实验室,这是一个在 Telefonica 研发场所设置的受控环境,用于运行实验,允许以受控方式部署复杂的网络场景并生成真实的标记数据集,用于训练受监督的 ML 组件并验证有监督和无监督的解决方案。 Mouseworld Lab 提供了一种启动客户端和服务器的方法,即使它们在 Internet 上与 Mouseworld 之外的客户端和服务器交互,也可以收集它们产生的流量,并最终在没有操作员干预的情况下为该流量添加标签。该环境部署在支持 NFV 的架构上,在协调器 (NFVO) 的管理下,根据需要扩展 ETSI NFV MANO 堆栈。
图 4 显示了 Mouseworld Lab 的详细图片,该实验室由在管道中交互的四个模块组成:启动器、数据收集器、特征提取器和标记器。

图 4. Telefonica研发场所的MouseWorld实验室。
Launcher 协调 Mouseworld 环境并运行实验,以生成不仅跨越 Mouseworld 内部网络而且跨越 Internet 的真实网络流量。该组件允许通过运行安装在一批 Linux 虚拟机中的真实客户端来产生三种基本类型的常规流量:网络、视频和文件托管(例如 Dropbox、OwnCloud)。此外,Launcher 还可以管理临时虚拟机,例如我们在研究工作中设置的包含 Monero 矿工的虚拟机,它还可以运行会话以使用 Ixia Breakingpoint 生成一组互补 Internet 协议的网络流量,一种商业工具,可以生成复杂的合成流量模式。
数据收集器模块收集单个实验生成的所有数据包。特征提取模块根据源和目的IP地址/端口号和传输协议的经典五元组将收集到的数据包分组为流,并调用外部模块获取每个流的特征集。在我们的实验中,我们使用了 Tstat 工具的修改版本,以便从流统计中得出一组标准 Netflow 功能以及我们对一组高信息功能的建议。修改后的 Tstat 不仅像在原始 Tstat 中那样在连接结束时以取证模式获取流特征,而且在不同的时刻实时获取流特征,这使我们能够训练和测试机器学习组件,即使只传输了流的几个数据包,也能识别加密流。
最后,Tagger 在每个实验执行期间使用 Launcher 输出的外部和日志信息自动为每个流添加标签,无需人工干预。由于流标记高度依赖于机器学习任务,因此该组件只是必须为每种类型的场景开发的 ad-hoc 标记器的简单包装。在我们的实验中,我们使用矿工(客户端)和加密服务器池的 IP 地址和端口对该组件进行了编码,以便将加密流与包含正常流量的其余流区分开来。请注意,标签仅用于训练和测试机器学习模型,当它们在生产环境中运行时不需要标签来生成预测。
Mouseworld 中部署的基础设施和配置如下所述。我们部署了 30 个虚拟机来生成常规流量(即 Web、视频和共享文件夹流)。 Web 和视频请求是使用 Chrome 无头浏览器生成的,共享文件夹(即文件托管)请求是使用 Dropbox 和 OwnCloud 的特定客户端生成的。使用指定了每种类型请求频率的配置文件,从客户端随机生成 Web、视频和共享文件夹请求。这些请求被随机发送到内部 Mouseworld 服务器和位于 Internet 上的外部服务器。值得注意的是,所有服务都生成了加密(例如 HTTPS 请求)和非加密(例如 HTTP 请求)流量请求。此外,IXIA BreakingPoint 工具还被配置为生成和注入各种 Internet 网络服务(Web、多媒体、共享文件夹、电子邮件和 P2P)的合成模式。 BreakingPoint 生成的流量也被配置为由加密和非加密流组成。
此外,我们还创建了三个加密挖掘 Linux 虚拟机。我们在所有三个虚拟机中都安装了 xmr-stak [31] 和 xmrig [32],并将它们配置为使用加密和非加密的 Stratum 连接。我们使用所有这些客户端来挖掘 Monero [33] (XMR) 加密货币,通常用于非法目的 [6]。加密客户端使用默认设置通过非加密 TCP 和加密 TLS 连接与公共矿池连接。每个矿工每小时被强制断开连接并重新连接,以模拟新的矿池连接。
我们设计了四个实验,将 Launcher 和 BreakingPoint 工具与不同的加密客户端和协议相结合。每个实验运行一小时,平均数据包速率约为每秒 1000 个数据包,生成数据集,其中包含 800 万个 TCP 流,其中 4000 个与 Stratum 相关。特别是:
-
在实验 1 中,BreakingPoint 工具与两个使用 TLS 加密连接的 xmr-stak 客户端和一个仅建立非加密 TCP 连接的 xmrig 客户端一起运行。
-
在实验 2 中,运行在 Mouseworld 虚拟机中的真实客户端启动以与位于 Internet 和 Mouseworld 内部网络中的服务器进行交互; 此外还部署了一个使用 TLS 加密连接的 xmr-stak 客户端和两个使用非加密 TCP 连接的 xmrig 客户端;
-
在实验 3 中,启动了真实客户端与两个使用 TLS 加密连接的 xmr-stak 客户端和一个仅建立非加密 TCP 连接的 xmrig 客户端的组合。
-
最后,在实验 4 中,BreakingPoint 工具与一个使用 TLS 加密连接的 xmr-stak 客户端和两个使用非加密流的 xmrig 客户端一起运行。
为训练和测试目的,将获得的四个数据集分成两个独立的子集。具体来说,将实验 1 和 4 的数据集加入 DS1(训练)数据集,并将实验 2 和 3 中收集的其他两个数据集合并到 DS2(测试)数据集。通过这种方式,可以认为 DS1 和 DS2 具有相同的性质,因为它们包含相似百分比的加密和非加密流量、互联网服务类型和加密挖掘协议流。值得注意的是,挖矿协议产生的流量与正常流量相比较小,在所有数据集中都会出现挖矿流量与正常流量的不平衡(1:5000),这带来了额外的挑战用于训练 ML 分类器。
DS1 数据集(1600 万个示例)被打乱并分成两组,用于超参数优化的训练 (85%) 和验证 (15%)。 DS2 数据集(1600 万个示例)仅用于最终测试目的。
B. 模型训练
对于我们的每个数据集,正确训练和测试 ML 模型的第一步是特征选择阶段。传统上,流量分类技术的深度数据包检测技术通过端口号检测或数据包有效载荷内容的解释来获取特征。然而,由于普遍使用加密方法来封装数据包内容(包括 TCP 或 UDP 端口号)以及政府越来越多地引入隐私法规以限制对数据包有效载荷数据的访问,这些技术往往受到越来越多的限制。为了克服这些限制,最近的机器和深度学习技术使用流描述作为机器学习模型的输入。这些描述由一组特征组成,这些特征是从外部可观察的流量属性获得的统计数据,例如每个流的持续时间和流量、数据包间到达时间、数据包大小和字节配置文件 [34]。
选择信息丰富的判别特征是在不同任务(如分类)中有效机器学习算法的关键步骤。特别是,机器学习分类器的性能不仅取决于模型之间的差异及其具体配置,还取决于输入特征的选择。如今,研究和工业界对一套可靠的功能没有达成强烈的共识,这些功能可以在所有场景中与机器学习一起表现良好。尽管如此,基于基于时间的统计特征(例如流的数据包的大小和数据包间时间,或数据包标头或有效载荷中字节分布的熵)的提议正在获得动力([35],[36])。
在过去几年中,网络流量分析正面临与新的、更复杂和未知的流量入侵相关的新挑战。特别是,要确定一组足够的特征来帮助获得稳定且高性能的机器学习模型以用于新场景(例如加密矿流检测)并不容易。出于这个原因,我们决定比较两组不同的特征,目的是确定它们对机器学习性能的影响,并证明使用更多信息特征,可以获得机器学习性能的显着提高。两组特征都不是专门为加密攻击量身定制的,因为它们反映了网络流的参数,因此它们可以用于其他网络流量场景(例如网络流量分类)。由于我们的目标是检测网络上的加密攻击,因此使用流特征进行流(例如 TCP 连接)识别似乎是合适的方法。
表 1. Tstat中选择的特征(所有特征可见http://tstat.polito.it/measure.shtml)
| C->S | S->C | Name | Metric(就是单位) | Desc |
|---|---|---|---|---|
| 3 | 17 | packets | - | 从客户端/服务器上保留的数据包总数 |
| 5 | 19 | ACK sent | - | ACK字段设为1后的段数 |
| 6 | 20 | PURE ACK sent | - | ACK字段设为1且无data后的segment数 |
| 7 | 21 | unique bytes | bytes | 在payload中发送的字节数 |
| 8 | 22 | data pkts | - | payload的段数 |
| 9 | 23 | data bytes | bytes | 在payload中传输的字节数,包括重传retransmission |
| 31 | - | Completion time | ms | 自第一个到最后一个数据包的数据流持续时间 |
| 32 | - | C first payload | ms | 客户端上,自第一个数据流段后至第一个带payload数据段 |
| 33 | - | S first payload | ms | 服务器上,自第一个数据流段后至第一个带payload数据段 |
| 34 | - | C last payload | ms | 客户端上,自第一个数据流段后至最后一个带payload数据段 |
| 35 | - | S last payload | ms | 服务器上,自第一个数据流段后至最后一个带payload数据段 |
| 36 | - | C first ack | ms | 客户端上,自第一个数据流段后至第一个ACK(不带SYN)数据段 |
| 37 | - | S first ack | ms | 服务器上,自第一个数据流段后至第一个ACK(不带SYN)数据段 |
| 45 | 52 | Average rtt | ms | 平均RTT计算测量数据段和相应的ACK之间经过的时间 |
| 46 | 53 | rtt min | ms | 在连接寿命期间观察到的最小RTT |
| 47 | 54 | rtt max | ms | 在连接寿命期间观察到的最大RTT |
| 48 | 55 | Stdev rtt | ms | RTT的标准差 |
| 49 | 56 | rtt count | - | 有效的RTT观察数 |
| 50 | 57 | ttl_min | - | 最短存活时间TTL |
| 51 | 58 | ttl_max | - | 最长存活时间TTL |
| 65 | 88 | RFC1323 ws | 0/1 | 发送窗口缩放(window scale)选项 |
| 66 | 89 | window scale | - | 经协商的缩放值[比例因子] |
| 67 | 90 | SACK req | 0/1 | SACK option set |
| 68 | 91 | SACK sent | - | SACK消息发送的数量 |
| 70 | 93 | MSS | bytes | 声明的MSS |
| 71 | 94 | max seg size | bytes | 观测到的最大段大小 |
| 72 | 95 | min seg size | bytes | 观测到的最小段大小 |
| 73 | 96 | win max | bytes | 声明的最小接收者窗口(已经通过窗口比例因子进行缩放) |
| 74 | 97 | win min | bytes | 声明的最大接收者窗口(已经通过窗口比例因子进行缩放) |
第一组 51 个特征被提议作为我们工作的一个新贡献,并且来自 Tstat 工具统计数据的一个子集。这些特征的集合在表 1 中有详细说明,其中 CS 代表客户端到服务器和 SC 服务器-到客户端的流量。 Tstat 工具 [37] 允许从传输层和应用层提取大量分类统计信息,并且不是为任何特定类型的网络流量或应用程序量身定制的
考虑到不检查数据包有效载荷的初始假设,我们不会使用 IP 地址或端口号或从应用层数据的统计数据得出的特征。此外,为了推导出这组特征,我们使用以下标准选择了 Tstat 统计数据:首先,我们没有考虑 Tstat 统计数据在不同时刻显示所有连接的恒定值,因为它们不包含任何信息(例如 c_rst_cnt、s_rst_cnt、c_isint、s_isint)。其次,我们对数据应用线性相关分析,以识别和删除高度相关的变量。在这种情况下,我们在使用此标准丢弃 Tstat 统计数据时采用了相当保守的方法,因为相关性分析仅显示变量之间的线性相关性,而神经网络往往会发现变量之间有趣的非线性关系。因此,我们没有使用此标准删除任何 Tstat 统计数据,以便为所有机器学习模型,特别是神经网络模型提供机会发现特征之间的非线性关系。最后,我们应用我们之前在网络和协议方面的专业知识来丢弃对机器学习应用无益的 Tstat 统计信息。特别是net_dup(网络数据包重复次数)、reordering(观察到的数据包重新排序次数)、rtx_RTO(由于超时到期重传的段数)和rtx_FR(由于快速重传而重传的段数,三个dup- ack)等被删除,因为它们代表了特定时间段内出现的网络流量拥塞情况的统计数据,而其他时间可能不会出现。
此外,作为双重检查机制,我们在使用随机森林模型训练模型后获得特征重要性值,我们观察到几乎所有特征的值范围为 0.12 到 0.01,除了 s_tm_opt(服务器发送的时间戳选项)显示一个非常小的值 0.0000184。这个结果强调没有任何特征子集比其他特征更重要,相反,所有选定的 Tstat 派生特征都有助于复杂模型的高性能。值得注意的是,当使用深度神经网络时,特征重要性不能那么容易获得,因此,推荐的方法是将所有输入特征提供给神经网络,让优化算法自己找到哪些特征信息量最大.关于神经网络决策的可解释性和可解释性及其与输入特征的关系是目前正在研究的主题,我们决定保留初始 51 个 Tstat 派生特征作为所有机器学习模型的输入,以便在相同的条件。
第二组功能将源自 IETF 标准 NetFlow/IPFIX 指标。最近在 [7] 中提出了这组八个特征,用于使用机器学习检测加密挖掘活动。这些派生特征是:
- 入站和出站数据包/秒;
- 入站和出站比特/秒;
- 入站和出站位/数据包;
- 比特入站/比特出站比率;
- 数据包入站/数据包出站比率。
因此,我们用三组特征评估了我们的机器学习模型:
- 在场景A 中,使用了NetFlow/IPFIX 指标;
- 在场景 B 中,仅使用了从 Tstat 统计得出的特征;
- 最后,在场景 C 中,Tstat 派生和 NetFlow/IPFIX 功能共同使用。
在特征选择阶段之后,我们执行超参数优化阶段,以找到最佳超参数以实现高度准确的模型。优化超参数被认为是构建机器学习模型中最棘手的部分之一,因为在构建模型时通过简单地猜测和测试这些值的几种组合几乎不可能获得最佳参数。另一方面,尝试一组超参数的所有值组合是不可扩展的,因为要测试的组合数量随着超参数的数量和每个超参数中要测试的值的范围呈指数增长。有几种启发式方法可以帮助找到这些最佳超参数,随机搜索是最流行和最有效的方法之一。顾名思义,评估的超参数组合是从超参数多维网格中随机选择的。
随机搜索的基本策略包括评估每个超参数值组合的验证分数,并将结果与超参数组合一起记录。在搜索结束时,选择产生最高验证分数的超参数,并在所有训练数据集上训练模型。最后,使用该模型对测试数据集进行预测。每次运行随机搜索时,都将超参数空间用作输入,算法会生成超参数值的随机组合以供尝试。除了在超参数空间中的可用值中随机选择下一个值之外,对随机搜索没有任何要求。
在我们的实验中,我们使用随机搜索算法 (RS) 来寻找训练每个模型的超参数值的最佳组合。在对每个模型进行了大量训练并使用了足够多的超参数组合后,我们选择了验证时 F1 分数最高的模型。每个机器学习模型至少使用了几十种不同的组合。在观察到搜索结果稳定后停止随机搜索(即在几次随机搜索迭代后没有出现更好的模型)表 2 显示了我们为每个模型优化的范围和超参数。
表 2. Hyperparameter的值
| Hyperparameter | 模型 | 值 |
|---|---|---|
| L2 regularization | LR | (, 100) |
| FCNN | (, 10) | |
| Max Depth | CART | (1, 200) or None |
| RF | (1, 200) or None | |
| #Trees | RF | (1, 200) |
| Pruning confidence | C4.5 | (, 1.0) |
| #Min. instances per tree | C4.5 | (2, 200) |
| Dropout | FCNN | (, 0.7) |
| Learning rate | FCNN | (, 1.0) |
| Class weight | FCNN | (1, 5) |
| #Layers | FCNN | (1, 5) |
| #Units per layer | FCNN | (1, 1000) |
在运行随机搜索之前,我们对基于全连接神经网络 (FCNN) 架构的不同深度学习模型进行了一些初步评估。我们使用前向旁路连接和批量归一化在 FCNN 中使用多达 10 个隐藏层运行这些初步评估,以避免梯度消失。据观察,使用大量层(例如 8 到 10)并没有产生比我们使用较少层(2 到 4)训练 FCNN 时更好的值。因此,在随机搜索过程中,我们将 FCNN 层的搜索范围从 1 层减少到 5 层。因此,我们训练并测试了浅(1-2 个隐藏层)和深(3-5 个隐藏层)全连接神经网络
请注意,类权重超参数的定义是为了管理加密挖掘用例上下文中数据集的不平衡性质。如前所述,正常连接与加密挖掘连接的比率约为 5,000,这对训练过程的最终结果产生负面影响。因此,在 FCNN 模型的训练过程中尝试了该参数的不同值,以调节优化算法的行为。随机森林和逻辑回归是使用 Scikit-learn 库实现进行训练的,其中 classweigth 参数试图解决这个问题。此外,FCNN 模型使用整流线性单元 (ReLU) 作为激活函数,因此没有对该参数进行超参数搜索。
八、实验结果
我们进行了一组实验,以评估多种机器和深度学习模型检测加密货币流并将其与正常流量连接区分开来的性能。在实验开始时定义了两个互补的目标。首先,为了证明复杂的机器学习模型(例如深度神经网络)比简单的模型表现更好,其次,为了表明与之前的特征相比,我们提出的 Tstat 特征集(表 1)显着提高了这些模型的性能提案。作为更简单模型的代表,我们选择了 [7] 中提出的 ML 模型(SVM、朴素贝叶斯和 CART 以及 C4.5 树),目的是在更现实的场景中将它们的结果与复杂的深度学习模型进行比较,如部署在我们的实验。此外,选择随机森林是因为它被广泛认为是性能最好的 ML 技术之一,而逻辑回归是一种极其简单的方法的代表。在接下来的段落中,我们将描述通过使用第 VII 节中详述的数据集创建和模型训练程序获得的结果。
A. 机器学习设置
我们的目标问题旨在预测加密矿流并将它们与其他网络流区分开来。因此,这个问题被建模为一个分类器,其中预期输出是一个二进制值:1 对应于分类器识别的加密连接,而 0 分配给其余的连接。
为了能够准确地对这两种类型的连接进行分类,我们基于先前在第六节中介绍的分类器训练和测试机器深度学习分类器。特别是,我们评估了全连接神经网络 (FCNN) 并与传统机器学习技术进行了比较,例如逻辑回归 (LR)、CART 和 C4.5 决策树 (CART, C4.5) 和随机森林 (RF)。值得注意的是,在初步实验中,我们将 SVM 和朴素贝叶斯分类器包含在要评估的机器学习技术集中。然而,我们观察到,与 CART 和 C4.5 树相比,这两种技术都表现不佳。因此,朴素贝叶斯和 SVM 被排除在我们与其他模型的实验比较之外。此外,仅使用一小部分训练数据集(1600 万个示例的 1/100),SVM 训练时间就需要两天时间。从表 6 中可以看出,其余模型在最坏的情况下使用整个数据集(1600 万个示例)训练模型的时间不超过 40 分钟。
我们使用了第 VII-B 节中详述的训练程序,对于每个模型,应用了以下步骤:1)执行特征选择阶段; 2) 在超参数空间上运行随机搜索,并使用获得的超参数组合训练模型; 3) 在验证集上使用 F1-score 对性能最好的模型进行排名; 4)在测试(DS2)数据集上测试最佳模型。
为了在验证和测试中对获得的结果进行比较和排名,我们计算了一组广泛用于分类问题的质量指标([38],[39]):准确率、宏观和微观版本的精度、召回率和 F1 分数和混淆矩阵。此外,计算了曲线下的 ROC 和 P-R 面积 (AUC),并绘制了它们相应的曲线。这些指标使我们能够衡量我们的模型在一组异构互联网连接中识别和检测加密货币流的质量
使用著名的 scikit-learn 库中可用的 Python 代码版本训练传统机器学习模型(LR、CART 和 RF)。由于在 scikit-learn 库中没有可用的 C4.5 实现,我们使用了 Weka 工具 [40] 中包含的 C4.5 的 J48 版本。深度学习模型 (FCNN) 是在 Python 中使用 Keras 框架 [41] 在 Tensorflow [42] 上实现的,以利用 GPU 加速。所有神经网络都使用 Adam 优化器 [27] 进行训练,以最大限度地减少交叉熵损失。在这种情况下,训练过程由一系列训练迭代组成。每次训练迭代包括 5 个 epoch,在每次迭代结束时,F1 分数在验证集上计算并用作提前停止标准(即在 10 次迭代后验证指标没有增强,训练过程停止)。无论如何,训练在 500 次迭代后停止。另外请注意,在训练 FCNN 时,将少量训练数据 (15%) 留出并用于在训练过程中提前停止 epoch 数,从而避免过度拟合和局部最小停滞。
B. 模型的结果和比较分析
使用之前描述的随机搜索程序和 DS1 数据集,我们针对每个场景 A、B 和 C 训练和验证了 LR、CART、C4.5 和 RF 的 15 个模型组合以及 FCNN 的 74 个模型组合。让神经网络模型有更多的超参数 ,需要更多的超参数组合才能找到大量具有良好性能的模型。
方案 A、B 和 C 获得的结果分别显示在表 3、4 和 5 中。 在这些表中,每一列都显示了测试数据集 (DS2) 上每个模型(FCNN、RF、CART、C4.5 和 LR)的最佳代表的测试结果。 使用它们在验证数据集中的排名结果在所有模型组合中选择每个模型的最佳代表。 每个模型的代表都通过其超参数的摘要进行标识,包括架构细节,使用紧凑符号进行描述,如下例所示:
1 | #1/75 FCNN |
应用的命名法如下:
- (第1行)
#X/Y modelName:
X 和Y 分别表示模型在测试排名中的位置和训练的模型组合总数。 回想一下,表格中显示的模型始终是验证的最佳模型。 因此,接近 1 的数字 X 表示在验证阶段获得良好性能的模型在使用不同的 DS2 数据集进行测试时表现一致。 因此,如果模型在验证的顶级模型中选择,我们可以对模型组合在实时生产场景中的性能充满信心。 - FCNN 模型添加以下值:
- (第 2 行)描述神经网络架构的值列表:[X0, X1, . . . , 习, . . . , Xn] 其中 n 是层数,Xi 是层 i 中的单元数。
- (第 3 行和第 4 行)Dropout、L2 正则化值、Adam 学习率和类权重值(即加密流类相对于表 2 中定义的正常流量类的权重)。
- 随机森林模型包括:
- trees的数量
- trees的最大depth limit。
- 逻辑回归模型显示应用的正则化系数。
- CART 模型指示树木的最大深度。
- C4.5 模型包括 置信值 © 和两个最流行分支中的最小实例数 (M)。
- (最后行)所有模型都显示了在验证中获得的 F1(marco) 值。
表 3. 场景A:使用NetFlow特征选择方法基于验证数据集的最佳模型的测试数据集(DS2 DataSet)的总体结果。
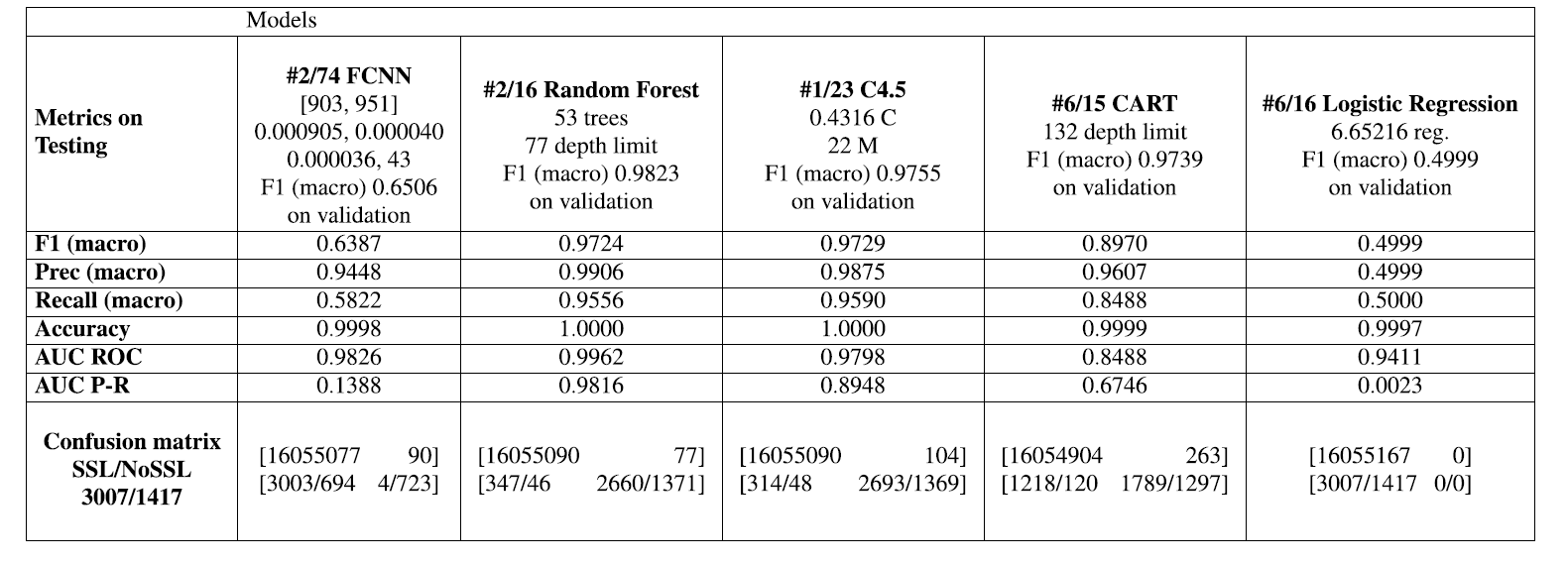
表 4. 场景B:使用TSTAT功能选择方法基于验证数据集的最佳模型的测试数据集(DS2 DataSet)的总体结果

表 5. 场景C:基于使用NetFlow和TSTAT功能选择方法基于验证数据集的最佳模型的测试数据集(DS2 DataSet)的总体结果。

表 3、4 和 5 显示了每个模型在测试数据集上计算的质量指标。 F1-score、Precision 和 Recall 宏值与 Accuracy、RoC 和 P-R 曲线下面积(AUC ROC 和 AUC P-R)一起呈现。 最后一行显示了混淆矩阵,其中 cyptomining 连接的值被分解为两个数字,以便更好地分析。 SSL值代表数字
加密的加密流和 NoSSL 代表未加密的流。
从全局来看,可以观察到:
a) 复杂模型(深度神经网络FCNN、随机森林和 C4.5)在所有场景中都比简单的策略(CART 和 LR)获得更好的结果;
b) 在场景 B 中获得了最好的结果,它建议利用 Tstat 特征作为机器学习模型的输入。 此外,结合使用 Tstat 和 NetFlow 功能的场景 C,与仅使用 Tstat 功能(场景 B)相比,没有获得任何可观察到的优势。
随机森林 (RF) 和 C4.5 是仅有的模型,即使在场景 A 的上下文中也能获得不错的结果。使用较少表达的特征集(NetFlow 特征),RF 获得了令人满意的 F1 分数值 0.9724,然而比在场景 B 和 C 中获得的结果差(0.9964 和 0.9957)。与 CART 决策树等更简单的方法相比,RF 的卓越性能是通过使用增强技术来解释的,该技术使其更能抵抗噪声等问题 [22]。可以观察到,在场景 A 中,77 个正常流量流被归类为加密(误报),但在场景 B 和 C 中只有 31 个和 25 个。然而,在场景 A 中产生了 393 个误报(未检测到的加密流),这是场景 B 和 C(33 和 50)中观察到的假阴性数量的 10 倍以上。这意味着仅使用 Netflow 功能,RF 无法检测到的加密流数量是使用 Tstat 功能(场景 B 和 C)时未检测到的加密流数量的 10 倍。关于这项工作的主要目标之一是提供机器学习方法来准确检测尽可能多的(恶意软件)加密流,这一结果表明,仅使用 Netflow 特征(场景 A)的 ML 模型似乎无法达到其目的与使用 Tstat 特征的 ML 模型相比(场景 B 和 C)。使用少量估计器(在 25 到 100 棵树之间)和适度的树深度限制(在 40 到 200 之间,一种没有深度限制的情况下)获得了 RF 的最佳结果。最好的 C4.5 模型获得了几乎相同的 F1 分数和混淆矩阵值,因此,我们可以得出结论,它们在三种情况下的性能大致相同。
FCNN 深度模型在场景 B 和 C 中的执行范围与 RF 相似,分别获得了 0.9902 和 0.9910 的 F1 分数(宏)值,并且误报和误报的数字大致相等。从架构的角度来看,为了获得最佳性能,只需要三个隐藏层,每层大约有 700-800 个神经元。然而,FCNN 在使用 NetFlow 功能时产生了非常糟糕的结果(场景 A)。最佳配置仅实现了 0.6387 的 F1 分数值,这表明相对于为该类别检测到的真阳性 (727),出现了大量的加密类别 (3697) 假阳性。此外,请注意,在 RF (393) 的情况下,误报的数量要小得多。我们推测,现有的类不平衡以及 Netflow 特征的中等质量不允许 NN 优化算法以相似的比例减少假阴性和阳性的数量并增加加密类的真阳性。
在所有三种情况下,CART 模型在训练中的 F1 值(0.9739、0.9975 和 0.9963)都比在测试中(0.8970、0.6767 和 0.6762)要高,这清楚地表明这些模型倾向于过度拟合训练数据集。此外,在场景 A 和场景 B 和 C 中分别观察到极高数量的假阴性(1338)和假阳性(16032 和 16055)。因此,我们不鼓励在生产环境中使用 CART 来检测加密流,因为这些模型在所有场景中都表现出缺乏泛化性以及大量误报和误报。有趣的是,当场景 A 中仅使用 Netflow 功能时,这些模型的泛化效果似乎稍好一些(测试中的 F1 分数为 0.8970)。我们推测场景 A 中使用的 Netflow 特征在训练期间提供的信息少于 Tstat 特征,因此,由此产生的过拟合没有场景 B 和 C 中那么严重。
逻辑回归模型只能使用 Tstat 特征(场景 B 和 C)正确训练,分别获得 0.9805 和 0.9789 的可观 F1 分数值。然而,在场景 A 中,LR 模型无法识别任何加密流,因为所有流都被归类为正常流量。场景 B 和 C 的混淆矩阵显示比 RF 和 FCNN 更多的假阳性和阴性。这一事实可能会排除这些简单模型在网络安全场景中的使用,在这些场景中,减少误报和误报至关重要。值得注意的是,使用显着的正则化,当使用 Tstat 特征(场景 B 和 C)时,该模型比 CART 模型的泛化效果要好得多。
关于测试数据集中加密 (SSL) 与非加密 (NoSSL) 加密连接的比率约为 2:1 - 数字可以在表 3、4 和 5 左下角的混淆矩阵单元格中找到 -场景 A 中 SSL 网络流量的误报比例是原始比例的两倍多:这个比例在 RF 中约为 7:1,在 C4.5 中为 6.5:1,在 CART 中为 10:1,在 FCNN 中为 4:1 .对于逻辑回归,此值无关紧要,因为模型无法对任何内容进行分类,因为所有流量都被预测为 0 类(正常流量)。当在场景 B 和 C 中使用 Tstat 特征时,随机森林和 CART 模型的加密流中误报的 SSL/NoSSL 比率为 2:1,C4.5 为 3:1,FCNN 模型约为 3:1,4 :1 用于逻辑回归模型,这清楚地表明 Tstat 功能有助于一致地识别加密流,即使它们被加密。
图 6 和图 7 清楚地表明,当使用 Tstat 特征时,RF C4.5 和 FCNN 模型在 ROC 和 PR 曲线中的决策函数表现出非常好的可分离性值,因为它们在 ROC/PR 曲线下的面积对于 RF 均高于 0.99 FCNN 和 C4,5 为 0.98。请注意,正如我们在实验中考虑的那样,P-R 曲线往往对不平衡分布相当敏感。在这种情况下,可以在 P-R 图中观察到,在 AUC 值为 0.6 且曲线形状非常接近对角线的情况下,CART 树无法实现良好的可分离性行为。值得注意的是,当使用 Netflow 特征时(图 VIII-B),只有 RF 和 C4.5 显示出不错的可分离性结果,相反,FCNN 产生了高度不稳定的行为,如左侧突然变为零的 PR 曲线所示右边是由于精度达到非常接近零的值。造成这种不稳定性的原因是(a)当决策阈值大于或等于 0.6(因此精度也为零)时,真阳性的数量(对于加密挖掘类)变为零,以及(b)假阳性的数量当决策阈值小于 0.5 时,阳性数突然从 86 变为 205,048,即真正的阳性数约为 700(因此,精度大约为零)。
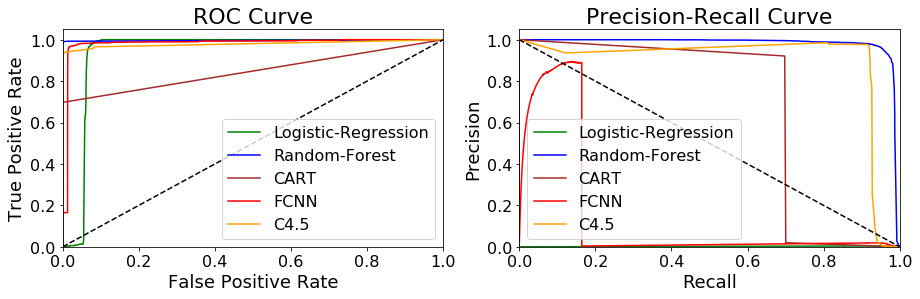
图 5. NetFlow方法提取特征下,ROC和P-R基于验证数据集所选择的最佳模型的测试数据集
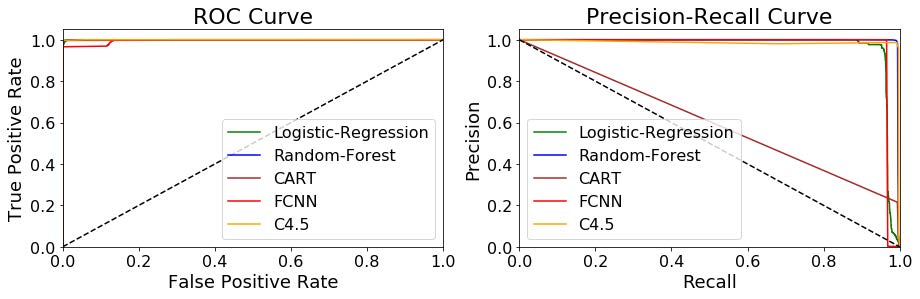
图 6. TSTAT方法提取特征下,ROC和P-R基于验证数据集所选择的最佳模型的测试数据集
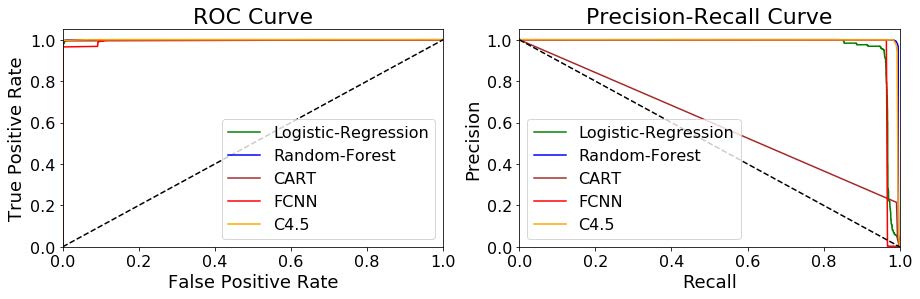
图 7. 组合方法提取特征下,ROC和P-R基于验证数据集所选择的最佳模型的测试数据集
根据这些结果,我们可以得出结论:(a)场景 A 中使用的 Netflow 特征集产生的模型比选择 Tstat 特征作为输入(场景 B 和 C)时的模型准确度低,以及(b)RF,C4.5和 FCNN 模型始终比 CART 和 Logistic 回归等简单模型获得更好的结果。特别是,使用 Tstat 特征和 RF、C4.5 和 FCNN 模型获得了最好的结果。这些模型实现了大约 0.99 的 F1-macro 值,反映出仅产生了极少数的误报和误报——不到加密流总数的 4%。相反,仅使用 Netflow 功能,假阴性的数量是真阳性的三倍,这突出了识别加密流时缺乏准确性。此外,作为漏报出现的 SSL/Non_SSL 加密流的比率高于整个加密流集,这反映了这些功能无法精确识别加密 (SSL) 加密流。未来的场景中,越来越多的加密流预计将被加密,这并不意味着只使用这组有限的功能。
最后,值得注意的是,最佳模型的高精度并不是以牺牲长时间的训练为代价的。它是信息丰富的特征(即 Tstat 特征)与复杂机器学习模型的结合,可实现高准确率、精确度和召回率。关于对三个特征集应用相同的训练过程,可以观察到,当我们使用信息量较少的特征(Netflow 特征集)时,性能显着下降。图 8 和图 9 显示了每个模型的训练时间和预测速度(图中绘制了平均值和标准差)。使用英特尔 i5-9400F、2.90 GHz、6 线程 cpu、64 GB RAM 和配备 GTX1080 GPU 的普通 PC 工作站进行训练和测试。可以观察到,对于 1600 万个示例,所有模型的训练时间始终低于 40 分钟,并且往往与输入特征的数量成正比。类似地,预测与模型复杂度成反比,并且使用相同的硬件在每秒数百万的范围内。请注意,C4.5 是使用 Weka 工具中可用的 J48 版本运行的,因此,它的预测性能明显低于其他直接用 Python 编码的模型。
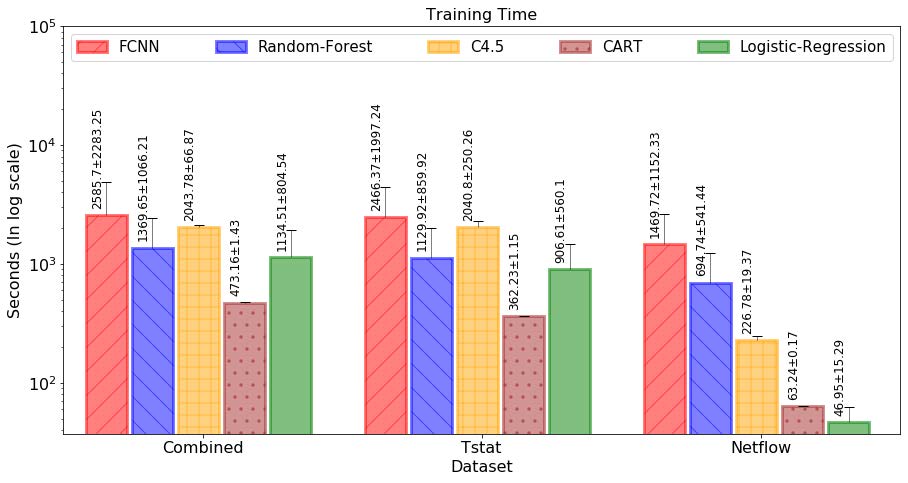
图 8. 模型在PC工作站上使用10个随机搜索执行计算的培训时间。
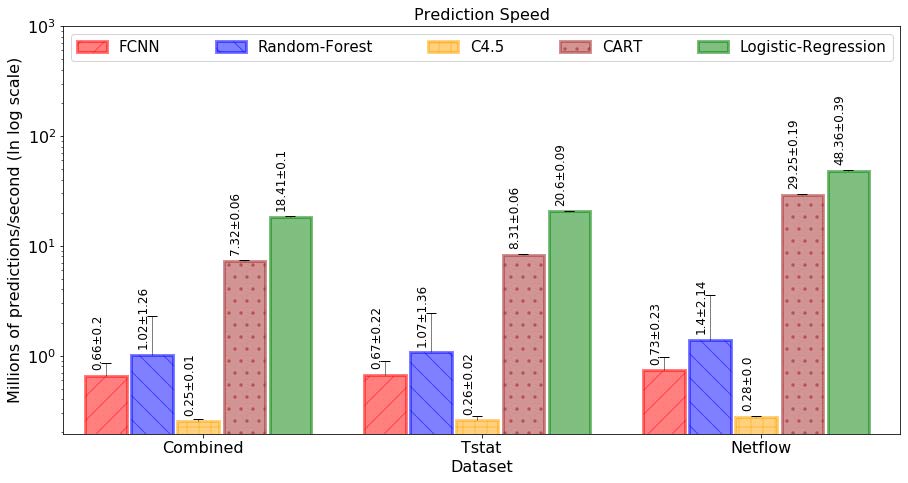
图 9. 模型在PC工作站上以10个随机搜索执行计算计算的预测速度。
C. 按数据包数量和连接持续时间划分的结果
为了研究模型的预测在流的整个生命周期中的稳定性,我们展示了先前对每个模型和场景进行验证的最佳性能配置的测试结果,这些模型和场景按传输数据包的范围和流持续时间分隔。在图 10 中,我们展示了为测试数据集中包含的网络流计算的测试指标,按传输数据包的范围对流进行分组。通过这种方式,我们可以确定需要传输多少个流数据包,以便能够以特定精度预测流是正常流量还是加密连接。此外,我们在测试数据集中显示了网络流的指标,在图 11 中按以秒为单位测量的时间段对流进行分组。这些指标允许我们估计需要多少秒才能以一定的精度识别流是加密还是正常的连接。
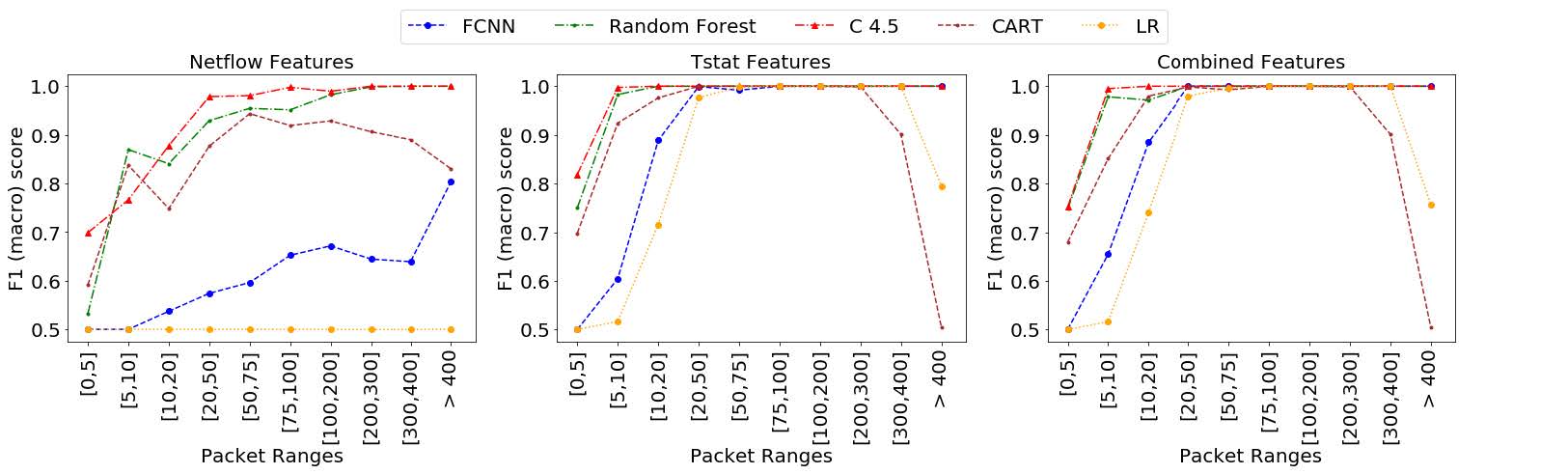
图 10. F1(marco)通过数据包范围进行测量的测试。
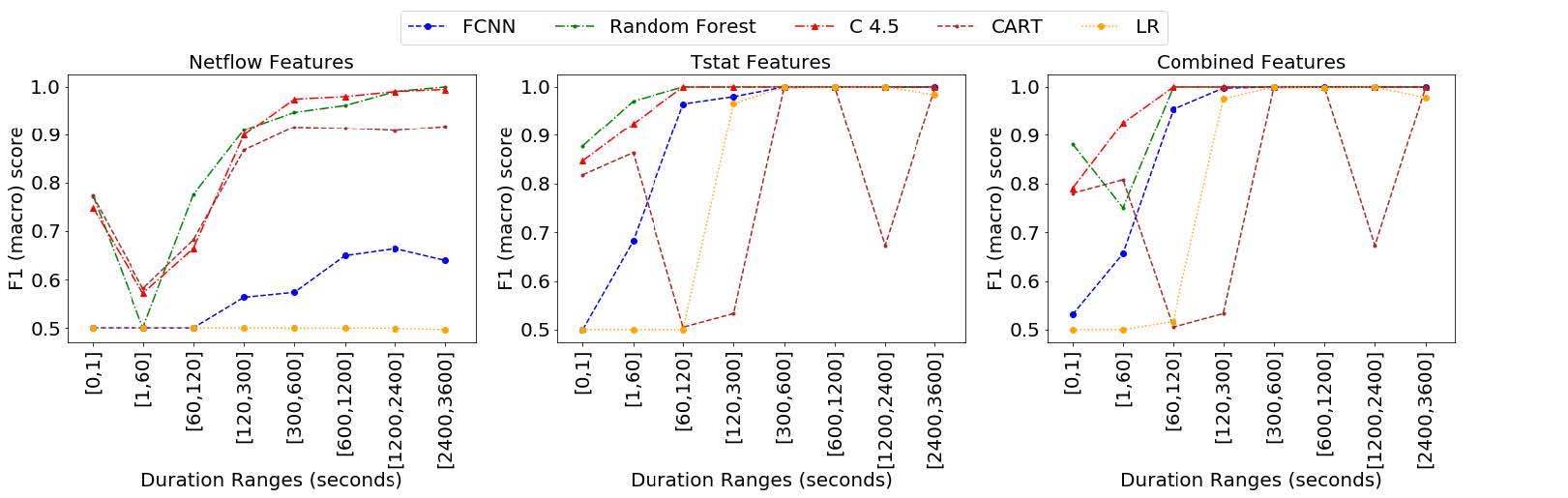
图 11. F1(marco)通过连接持续时间范围进行测量的测试。
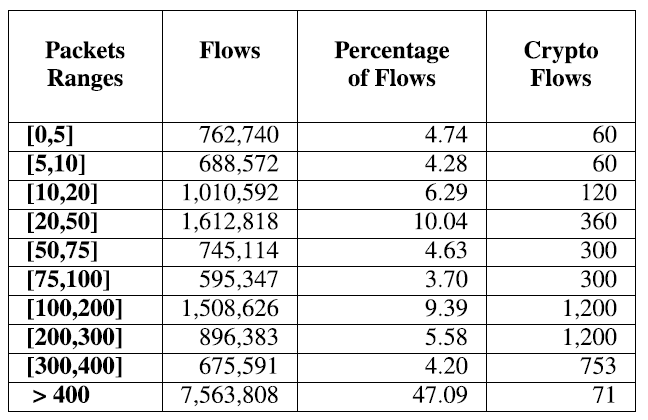
图 10 显示了在测试场景 A、B 和 C 的最佳性能模型配置时获得的宏 F1-Score 值。结果按表示从客户端发送到客户端的所有数据包总和的数据包间隔分隔。服务器以及在连接期间从服务器到客户端。请注意,TCP 连接的建立涉及 3 个数据包的传输,而加密的新 SSL 连接的建立涉及至少 4 个附加数据包的传输(不恢复)。因此,实际上不可能识别 SSL 连接是承载少于 7 个数据包的正常流还是加密流。此外,对于未加密的 TCP 连接,我们需要至少 4 个数据包来识别它,因为前三个数据包对所有(加密和非加密)TCP 连接都是通用的。回想一下,作为我们分析的基本假设,我们没有使用 IP 地址或端口作为输入特征。表 6 显示了包含在每个数据包范围内的流的数量,作为绝对值和占总数的百分比,以及落在该区间内的加密流的数量。
表 6. 根据数据包范围分离的 网络流量(总数 与 总数的百分比)数 和 挖矿流量数
使用 Netflow 特征分析获得的结果,可以观察到,除了 RF 和 C4.5 需要传输至少 200 个数据包才能获得大于 0.99 的 F1 分数外,这两个模型在任何时间间隔都没有取得好的结果. RF 和 C4.5 模型的这个结果在实践中不是很有用,考虑到与正常流量速率相比,加密流的传输速率极低,因此,从创建到识别加密货币大约需要 30-45 分钟流量精度高(F1 分数为 0.99)。此外,CART 模型表现出显着缺乏稳定性,因为 F1 分数在超过 300 个数据包的流中开始下降。然而,FCNN、C4.5 和 RF 模型中的 F1 分数值显示出单调递增的行为,并且永远不会像 CART 模型那样不稳定。无法使用这些特征训练逻辑回归,因此在所有间隔中始终获得 0.5 的 F1 分数。相反,通过使用 Tstat 特征 FCNN,C4.5 和 RF 在少量数据包(RF 为 10,C4.5 为 75,FCNN 为 75)后获得 1 的 F1 分数(100% 的准确度、精确度和召回率)。 CART 和 LR 在数据包很少的情况下也达到了 1 的 F1 分数,但与前一种情况一样,当数据包数量增加(CART 中的 200 个数据包和 LR 中的 400 个数据包)时,它们会变得不稳定(降低它们的 F1 分数)。在场景 C 中使用组合 Netflow 和 Tstat 特征的结果显示出与场景 B 相似的结果,但在 FCNN 的情况下略有增强,仅用 20 个数据包实现了 F1 分数 1。
图 11 显示了每个模型的 F1(marco) 分数结果,并按时间间隔分隔。在每个时间间隔中,我们包括自建立以来一直处于活动状态的流,其秒数落在此范围内。因此,相同的流可以在不同的时刻被采样,其特征在同一数据集和不同的时间间隔中出现多次。例如,一个总持续时间为 200 秒的 TCP 连接将在 [0,1]、[1,60]、[60,120] 和 [120,300] 间隔中显示为不同的流发生。表 7 显示了流的总数和百分比,以及每个间隔中出现的加密流的数量。
表 7. 根据连接持续时间范围分离的 网络流量(总数 与 总数的百分比)数 和 挖矿流量数
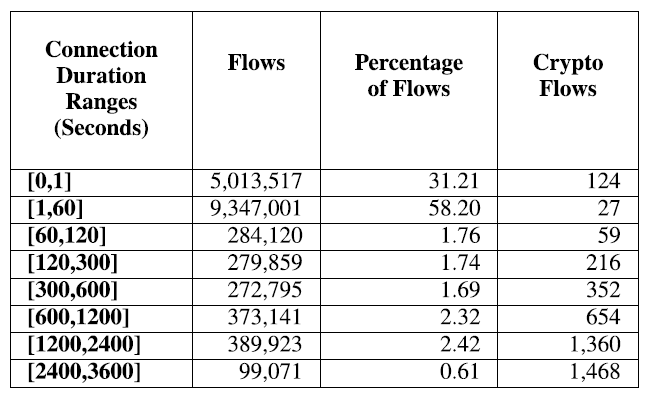
图 11 中报告的结果与按数据包范围分离结果时获得的结果相似。使用 Netflow 功能时,只有 RF 和 C4.5 模型表现良好,但只有在流持续时间大于 2400 秒时才能获得 0.999 的 F1 分数。请注意,在持续 1200 秒或更长时间的一组流中,加密连接的百分比远大于其余时间间隔,包括存在较短的流(表 7)。这种显着差异可以通过以下事实来解释:加密协议倾向于长时间建立连接,而这在正常流量中并不那么频繁。因此,与其余时间间隔相比,对持久流进行更精确的分类更容易。使用 Tstat 特征,RF 和 C4.5 在 60 秒后获得完美的分类(F1 分数为 1),而 FCNN 需要一些额外的时间(300 秒)。当流动持续时间较长时,CART 和逻辑回归表现出先前评论的不稳定。当在场景 C 中组合这两组特征时,与仅使用 Tstat 特征的模型相比,没有出现显着差异。
根据在按数据包或时间间隔分隔流时获得的结果,我们可以得出结论:(a)使用 Tstat 特征以及在 RF 和 C4.5 模型的情况下,获得了最佳结果(F1 得分为 1)一旦流传输了 10 个数据包或在流创建后仅经过 60 秒,并且 (b) RF、C4.5 和 FCNN 模型即使在仅使用 Netflow 特征时也没表现出不稳定(即,在这些模型中,F1-score单调增加,流中传输的数据包数量)。然而,CART 和逻辑回归模型表现出不稳定的行为。此情况发生在流中的数据包数量 在CART达到200 和 LR中达到400,或是,当流中的 数据包存活时间,在CART中超过1200s 和 LR中超过2400s。此结果可能会妨碍它们在实际生产环境中的使用。
九、结论和未来工作
我们设计、训练和测试了一组用于检测加密活动的机器和深度学习模型。我们选择了几个复杂的模型,例如深度神经网络、随机森林和 C4.5,以便将它们的性能与已知研究进行比较。作为相对于其他提议的新颖性,并且为了评估现实场景中的机器学习性能,我们的实验中考虑了正常和加密流量的加密和非加密流。作为主要贡献,我们提出了一组从 Tstat 工具统计中派生的信息丰富的新特征,以测试使用信息丰富的特征是否可以提高复杂模型的机器学习性能。我们使用 Tstat 工具为每个流派生了这组 51 个特征,并从 IETF 标准 NetFlow/IPFIX 指标中提取了第二组 8 个特征。
我们在 Telefonica 研发场所的 Mouseworld 实验室建立了一个受控的网络环境,使用真实的客户端和服务器来生成与正常流量(网上冲浪、视频和音频流、云存储、文件传输、电子邮件和 P2P)竞争的加密流量的真实实验除其他外)通过具有 Internet 连接的专用网络。 Cryptomining 客户端连接到 Internet 中的真实矿池,Monero 被选为我们实验的加密货币,因为它是迄今为止网络犯罪分子最喜欢的加密货币。 Monero 客户端运行 Stratum 协议,这是用于分发采矿过程的最广泛的协议。不仅为 Stratum 协议而且为其余流量建立了加密和普通连接,以便生成真实的流量跟踪。实验产生的流量被用于两个不同的任务。首先,捕获、标记和存储流量,用于训练监督机器学习模型。后来,流量被实时输入到机器学习模型中以进行测试。配置了三个场景,第一个使用 Netflow 派生特征,第二个仅使用 Tstat 派生特征,最后一个加入两组特征。
最好的结果是使用从 Tstat 派生的特征集获得的,值得注意的是,加入这两组特征(Tstat + Netflow),相对于仅使用 Tstat 特征,我们没有获得任何可观察到的优势。相反,代表技术当前状态的 Netflow 派生特征集在预测中产生了不稳定和不良性能,因此,我们建议工业界在使用机器和深度学习时应采用更详尽的特征以获得预期的性能和稳定性。此外,当随机森林、C4.5 和深度神经网络与 Tstat 特征结合使用时,加密加密连接的检测与普通(非加密)连接的性能相似。另一方面,当使用更简单的机器学习模型或 Netflow 功能时,加密加密流的检测缺乏精度和准确性,这与使用非加密加密流获得的结果成比例地更大。
根据所获得的结果,可以得出结论,我们提出的使用足够详尽的特征作为复杂机器学习模型(例如随机森林、C4.5 或全连接深度神经网络)的输入的提议,允许部署精确、准确和稳定根据行业要求检测加密活动的机制。
未来的工作将通过使用不同的加密协议和加密货币的新实验来扩展当前的研究,这可能意味着设计更复杂的模型来学习新的加密活动模式。
引用
[1] J. Lewis, The Economic Impact of Cybercrime—No Slowing Down.
Santa Clara, CA, USA: McAfee, 2018.
[2] S. Nakamoto. (2008). Bitcoin: A Peer-to-Peer Electronic Cash System.
[Online]. Available: https://git.dhimmel.com/bitcoin-whitepaper/.
[3] Deadcoins. Deadcoins Curated List of Cryptocurrencies and ICOs.
Accessed: Feb. 23, 2020. [Online]. Available: https://deadcoins.com
[4] L. Ren and S. Devadas, ‘‘Bandwidth hard functions for ASIC resistance,’’ in Theory of Cryptography, (Lecture Notes in Computer Science),
vol. 10677. Cham, Switzerland: Springer, 2017, pp. 466–492.
[5] GithubRepository, Tevador. (2019). RandomX: Experimental Proof of
Work Algorithm Based on Random Code Execution. [Online]. Available:
https://github.com/tevador/RandomX
[6] S. Pastrana and G. Suarez-Tangil, ‘‘A first look at the crypto-mining
malware ecosystem: A decade of unrestricted wealth,’’ in Proc. Internet
Meas. Conf., Oct. 2019, pp. 73–86.
[7] J. Z. I. Munoz, J. Suarez-Varela, and P. Barlet-Ros, ‘‘Detecting cryptocurrency miners with NetFlow/IPFIX network measurements,’’ in Proc. IEEE
Int. Symp. Meas. Netw. (M&N), Jul. 2019, pp. 1–6.
[8] S. Haber and W. S. Stornetta, ‘‘How to time-stamp a digital document,’’
J. Cryptol., vol. 3, no. 2, pp. 99–111, Jan. 1991.
[9] Braiins Systems. Stratum V2 | The Next Generation Protocol for
Pooled Mining. Accessed: Jan. 23, 2020. [Online]. Available:
https://stratumprotocol.org/
[10] Braiins Systems. Stratum Mining Protocol. Accessed: Jan. 23, 2020.
[Online]. Available: https://slushpool.com/help/topic/stratum-protocol/
[11] JSON-RPC Working Group. JSON-RPC 2.0 Specification. Accessed:
Feb. 23, 2020. [Online]. Available: https://www.jsonrpc.org/specification
[12] R. Recabarren and B. Carbunar, ‘‘Hardening stratum, the bitcoin pool
mining protocol,’’ Proc. Privacy Enhancing Technol., vol. 2017, no. 3,
pp. 57–74, Jul. 2017.
[13] A. Swedan, A. N. Khuffash, O. Othman, and A. Awad, ‘‘Detection and
prevention of malicious cryptocurrency mining on Internet-connected
devices,’’ in Proc. 2nd Int. Conf. Future Netw. Distrib. Syst. (ICFNDS),
2018, pp. 23:1–23:10.
[14] R. K. Konoth, E. Vineti, V. Moonsamy, M. Lindorfer, C. Kruegel, H. Bos,
and G. Vigna, ‘‘MineSweeper: An in-depth look into drive-by cryptocurrency mining and its defense,’’ in Proc. ACM SIGSAC Conf. Comput.
Commun. Secur., Jan. 2018, pp. 1714–1730.
[15] D. Carlin, P. OrKane, S. Sezer, and J. Burgess, ‘‘Detecting cryptomining
using dynamic analysis,’’ in Proc. 16th Annu. Conf. Privacy, Secur. Trust
(PST), Aug. 2018, pp. 1–6.
[16] J. Liu, Z. Zhao, X. Cui, Z. Wang, and Q. Liu, ‘‘A novel approach for
detecting browser-based silent miner,’’ in Proc. IEEE 3rd Int. Conf. Data
Sci. Cyberspace (DSC), Jun. 2018, pp. 490–497.
[17] A. Kharraz, Z. Ma, P. Murley, C. Lever, J. Mason, A. Miller, N. Borisov,
M. Antonakakis, and M. Bailey, ‘‘Outguard: Detecting in-browser
covert cryptocurrency mining in the wild,’’ in Proc. World Wide Web
Conf. (WWW), 2019, pp. 840–852.
[18] J. Berkson, ‘‘Application of the logistic function to bio-assay,’’ J. Amer.
Stat. Assoc., vol. 39, no. 227, pp. 357–365, Sep. 1944.
[19] J. Cramer, ‘‘The origins of logistic regression,’’ Tinbergen Inst. Discuss.
Papers 02-119/4, 2002.
[20] D. Steinberg, ‘‘CART: Classification and regression trees,’’ in The Top
Ten Algorithms Data Mining, X. Wu and V. Kumar, Eds. London, U.K.:
Chapman & Hall, 2009, ch, 10.
[21] J. R. Quinlan, C4.5: Programs for Machine Learning. Amsterdam,
The Netherlands: Elsevier, 2014.
[22] L. Breiman, ‘‘Random forests,’’ Mach. Learn., vol. 45, no. 1, pp. 5–32,
2001.
[23] T. En-Najjary, G. Urvoy-Keller, M. Pietrzyk, and J.-L. Costeux,
‘‘Application-based feature selection for Internet traffic classification,’’ in
Proc. 22nd Int. Teletraffic Congr. (lTC), Sep. 2010, pp. 1–8.
[24] T. En-Najjary and G. Urvoy-Keller, ‘‘A first look at traffic classification in
enterprise networks,’’ in Proc. 6th Int. Wireless Commun. Mobile Comput.
Conf. ZZZ (IWCMC), 2010, pp. 764–768.
[25] Y. Wang and S.-Z. Yu, ‘‘Machine learned real-time traffic classifiers,’’
in Proc. 2nd Int. Symp. Intell. Inf. Technol. Appl., vol. 3, Dec. 2008,
pp. 449–454.
[26] J. Li, S. Zhang, Y. Xuan, and Y. Sun, ‘‘Identifying skype traffic by random
forest,’’ in Proc. Int. Conf. Wireless Commun., Netw. Mobile Comput.,
Sep. 2007, pp. 2841–2844
[27] D. P. Kingma and J. Ba, ‘‘Adam: A method for stochastic
optimization,’’ 2014, arXiv:1412.6980. [Online]. Available:
http://arxiv.org/abs/1412.6980
[28] D. E. Rumelhart, G. E. Hinton, and R. J. Williams, ‘‘Learning
internal representations by error propagation,’’ in Parallel Distributed
Processing: Explorations in the Microstructure of Cognition, vol. 1.
Cambridge, MA, USA: MIT Press, 1986, pp. 318–362.
[29] A. Saied, R. E. Overill, and T. Radzik, ‘‘Detection of known and unknown
DDoS attacks using artificial neural networks,’’ Neurocomputing, vol. 172,
pp. 385–393, Jan. 2016.
[30] A. Pastor, A. Mozo, D. R. Lopez, J. Folgueira, and A. Kapodistria, ‘‘The
mouseworld, a security traffic analysis lab based on NFV/SDN,’’ in Proc.
13th Int. Conf. Availability, Rel. Secur. (ARES), 2018, pp. 57:1–57:6.
[31] fireice-uk. FIREICE-UK/XMR-STAK: Free Monero RandomX Miner and
Unified CryptoNight Miner. Accessed: Dec. 28, 2019. [Online]. Available:
https://github.com/fireice-uk/xmr-stak/
[32] Xmrig Team. XMRIG/XMRIG: RandomX, CryptoNight, AstroBWT and
Argon2 CPU/GPU Miner. Accessed: Jan. 23, 2020. [Online]. Available:
https://github.com/xmrig/xmrig
[33] The Monero Project. Home | Monero-Secure, Private, Untraceable.
Accessed: Feb. 23, 2020. [Online]. Available: https://www.getmonero.org/
[34] T. T. T. Nguyen and G. Armitage, ‘‘A survey of techniques for Internet
traffic classification using machine learning,’’ IEEE Commun. Surveys
Tuts., vol. 10, no. 4, pp. 56–76, 4th Quart., 2008.
[35] A. Dainotti, A. Pescape, and K. Claffy, ‘‘Issues and future directions in
traffic classification,’’ IEEE Netw., vol. 26, no. 1, pp. 35–40, Jan. 2012.
[36] A. Habibi Lashkari, G. Draper Gil, M. S. I. Mamun, and A. A. Ghorbani,
‘‘Characterization of tor traffic using time based features,’’ in Proc. 3rd Int.
Conf. Inf. Syst. Secur. Privacy, 2017, pp. 253–262.
[37] A. Finamore, M. Mellia, M. Meo, M. M. Munafo, P. D. Torino, and
D. Rossi, ‘‘Experiences of Internet traffic monitoring with tstat,’’ IEEE
Netw., vol. 25, no. 3, pp. 8–14, May 2011.
[38] G. Shobha and S. Rangaswamy, ‘‘Machine learning,’’ in Computational
Analysis and Understanding of Natural Languages: Principles, Methods and Applications (Handbook of Statistics), vol. 38, V. Gudivada
and C. Rao, Eds. Amsterdam, The Netherlands: Elsevier, 2018, ch. 8,
pp. 197–228.
[39] A. Mozo, I. Segall, U. Margolin, and S. Gomez-Canaval, ‘‘Scalable prediction of service-level events in datacenter infrastructure using deep neural
networks,’’ IEEE Access, vol. 7, pp. 179779–179798, 2019.
[40] M. Hall, E. Frank, G. Holmes, B. Pfahringer, P. Reutemann, and
I. H. Witten, ‘‘The WEKA data mining software: An update,’’ ACM
SIGKDD Explor. Newslett., vol. 11, no. 1, pp. 10–18, 2009.
[41] F. Chollet. (2015). Keras. [Online]. Available: Available: https://keras.io
[42] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin,
S. Ghemawat, G. Irving, M. Isard, and M. Kudlur, ‘‘Tensorflow: A system
for large-scale machine learning,’’ in Proc. 12th USENIX Symp. Oper. Syst.
Design Implement. (OSDI), 2016, pp. 265–283.