Dynamic Game on blockchain-based Federated Learning
Mobile Devices Strategies in Blockchain-Based Federated Learning: A Dynamic Game Perspective
Sizheng Fan; Hongbo Zhang; Zehua Wang; Wei Cai
IEEE Transactions on Network Science and Engineering
- 系统建模和制定:我们提出并实施了一种基于智能合约的激励机制,以鼓励移动设备参与 FL 任务。在这种情况下,提出了两种移动设备在 FL 任务中的策略模型。
- 动态博弈分析:据我们所知,这是第一个为 FL 动态博弈建模的工作,为进一步研究奠定了基础。我们证明了两个模型的纳什均衡(NE)和混合策略NE的存在性,并提出了相应的两种算法来实现。仿真结果证明了两种算法的收敛性,与 DSM 相比,CSM 可以有效地提高移动设备的收益。
Dynamic Game for Blockchain-Based Federated Learning 基于区块链的联邦学习动态博弈
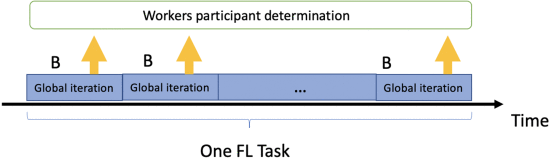
FL 任务过程由多个全局迭代组成,如图 3 所示。FL 任务由多个全局迭代组成。在每一次全局迭代中,请求者会在每次全局迭代中公布一个固定的奖励 ,由workers决定是否参与每一次全局迭代。我们将请求者和移动设备之间的交互建模为动态游戏。相互作用可以按以下顺序说明。
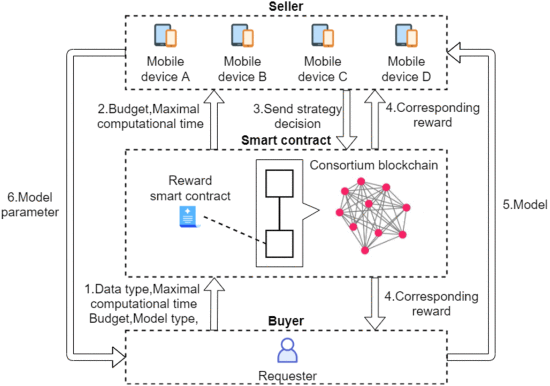
如图 4 所示,结合第 III 节中提到的基于联盟区块链的 FL 系统,请求者将发布她/他的任务需求,包括数据类型、模型类型(即卷积神经网络(CNN)、递归神经网络(RNN)), 最大计算时间 和 FL 任务开始时的预算 (步骤 1)。
Dynamic Game for Blockchain-Based Federated Learning
下面将显示在一次全局迭代中请求者与移动设备之间的交互。给定固定请求者的固定预算 ,最大计算和通信时间 (步骤2),每个移动设备 可以根据其他移动设备在当前全局迭代中的策略来决定她/他的策略过去并将其记录在区块链上(第 3 步)。
收到移动设备的信息后,智能合约将计算奖励(第 4 步)。移动设备将接收请求者的模型并开始使用其本地数据集进行训练(第 5 步)。完成训练过程后,移动设备将模型参数发送给请求者(步骤 6)。
在每次全局迭代中重复图 4 中的步骤 3、4、5 和 6。我们假设移动设备在每次全球迭代中都保持连接。每个移动设备的目标是在一次全局迭代中选择最佳策略,使她/他在整个 FL 任务中的预期收益最大化。
Incentive Mechanism Design 激励机制设计
在我们的 FL 模型中,请求者将在每次全局迭代中提供预算 B ,并与 M 移动设备竞争预算。移动设备将在每次全局迭代中将其策略决策(即使用的数据大小)发送给智能合约。我们使用 sj,n 表示移动设备 mj 在 n th全局迭代中选择的使用的数据大小,
FL 中现有的大多数激励机制都具有很高的复杂性 [26]、[28]。然而,FL 中有效的激励机制应该是低复杂性和易于实施的。每次全局迭代的实时性要求是移动设备在下一次全局迭代之前收到请求者的补偿,这可以帮助他们在接下来的全局迭代中做出决策。此外,移动设备经常面临电量不足、信号弱等问题。因此,激励机制应该具有较低的计算复杂度,节省移动设备的等待时间。本文提出的激励机制如下图所示。
\begin{equation*} p_{j, n} = B \frac{s_{j, n}}{s_{j, n} + \sum _{i \ne j}s_{i, n}} \tag{5} \end{equation*}
从式(5)我们可以了解到,请求者在当前全局迭代中根据移动设备的数据大小按比例将其固定预算分配给一组移动设备。
离散策略模型(DSM)
在本文中,我们从移动设备的角度考虑两种策略模型:离散策略模型(DSM)和连续策略模型(CSM)。 DSM 意味着移动设备可以决定是否参与 FL 任务。如果移动设备决定加入,她/他的所有数据都将用于训练模型。而CSM是指移动设备可以确定FL任务中使用的数据百分比。受 FL 迭代交互的启发,我们将移动设备的决策问题建模为动态游戏,以解决训练过程中信息不完整的问题。具体来说,在联盟链系统的赋能下,即使移动设备不知道其他人的个人信息,包括总数据量和训练成本,她/他也可以观察其他移动设备的策略历史并调整她/他的策略以最大化 FL 任务中的收益。