以太坊链上分析
解决问题
以太坊(-like)平台异常交易
异常:
- 诈骗
- 跑路
- 勒索
- 黑客攻击
- 洗钱
- 恐怖主义
- 反动
- …
希望做到:
- 识别、检测
- 监控
- 预防
以太坊
简单说明区块链生态相关应用以及其中图模型
链上
普通交易
目前大部分GNN做的分析部分,基于etherscan的label
关系:
- 地址 -[交易]- 地址
代币交易
代币主要指代符合ERC20标准的合约中定义的可交易的资产,包含了普通代币以及稳定币(USDT、USDC)
图同普通交易
DeFi
DeFi=Decentralized Finance去中心化金融。主要以去中心化交易所为主,可以实现借贷、杠杆。
所有交易对之间交易需要架设流动池作为基础,所有人都可参与流动池建设,可获得fee。
存在项目方挤兑社区流动池跑路现象rugpull
关系:
- 交易者视角
- 构建者视角
NFT
NFT=Non-Fungible Token,符合ERC721标准,是一种特殊的代币,每个代币都是独一无二的。一般与图片等媒体元素绑定。
新安全热点:杰伦NFT被偷
关系:
- NFT的mint(“开采”)
- 私下转移
- OpenSea交易平台上授权交易
DAO
DAO=decentralized autonomous organization去中心化自治组织
目前基本借用链外工具,在后续说明
PoW -> PoS
上个月以太坊完成The Merge升级。之前以太坊产出都源自于“挖矿”(以太坊供应量是无限的,没有衰减
关系(“挖卖提”):
- 矿池 - 矿工 [- 交易所 …]
现状:以太坊现在已经经过The Merge更新转为了一个基于PoS共识的区块链。
https://mp.weixin.qq.com/s/rwIkZuRPZtoOKPisCOobEQ
质押带来的新生态
关系:
- 质押提供者 - 质押账户 - 收益接受者
- 质押提供者 - 质押池 - 收益接收者
- 质押提供者 - 质押DApp - 收益接收者 (多对多)
链下
基本上功能=微博
关系:
- #topic
- follow
- star(点赞)、retweet(转发)
Discord
流行的社区建设平台(以前也有用Slack),比较松散的群聊
在实际处理proposal时会有较正规审批流程(基于合约)
关系:
- channel
- @Mention
- 上下文
- 点击emoji
- 链上request、offering、review…
Reddit, bitcointalk …
论坛形式的交流社区(现在流行用discourse
- Topics & replies
- Likes
标签
Misttrack:
- 1000k+ labeled
- 2000k+ nolabel
综述
Graph Analysis of the Ethereum Blockchain Data: A Survey of Datasets, Methods, and Future Work
摘要——以太坊是目前使用最活跃的第二大区块链平台,由人类用户、智能合约(自治代理)、以太币(原生加密货币)、代币(数字资产)、dApps(去中心化应用程序)和 DeFi(去中心化金融)。以太坊中的这些关键参与者通过交易和合约调用相互交互。鉴于高度连接的结构,基于图的建模是分析存储在以太坊区块链中的数据的最佳工具。最近,一些研究工作对公开可用的以太坊区块链数据进行了图形分析,以揭示对其交易和重要下游任务的洞察,例如加密货币价格预测、地址聚类、网络钓鱼诈骗和假币检测。在这项工作中,我们对现有文献进行了深入调查。我们根据出版年份、地点、核心排名和作者的隶属关系、数据使用和图形构建、使用的图形挖掘和机器学习技术以及它们得出的新见解对它们进行分类。最后,我们讨论了我们对未来工作的建议。我们的文章将对数据科学家、研究人员、金融分析师和区块链爱好者有所帮助。索引词——区块链、以太坊、网络分析
聚类
etherclust
Address Clustering Heuristics for Ethereum
由于比特币和以太坊在交易模式上的区别,现有的用于比特币的地址聚类方法不适用于以太坊的交易模型
- 向同一存款地址发送资金的多个地址可能属于同一实体
- 用户通常会将空投获得的所有token汇总到一个账户,可以利用这个模式来识别多次接收token的单个实体。
- 用户使用approve函数授权自身拥有的其他地址,自授权
(写的不如别人
社区检测
Community Detection in Blockchain Social Networks
In this work, we focus on the smart contract transactions and define the Ethereum social network as a bipartite social graph.
Particularly, we are interested in those smart contract transactions specific for initial coin offering (ICO) events. Based on their bipartite graph, we introduce an effective community detection algorithm for low-rank signals to group users into different clusters
As a blockchain network, Ethereum is different from Bitcoin in many aspects. Particularly, Ethereum is not only a platform for providing ETH coin transactions, but also a programming language that enables users to build and publish distributed applications via the smart contract. In Ethereum, each user generates a pair of asymmetrically encrypted public key and private key to join the network. Each public key could be considered as a node in our Ethereum social network. In Ethereum, there are two types of accounts: EoAs and CAs. EoAs are considered as individual users in the external world while CAs are the contracts that could connect EoA users. Both EoAs and CAs are presented by unique hash addresses
在本文 中,我们使用ICO事件和代币交易额作为特征来定义二方图,而实际上它可以是任何其他类型的智能合约,连接EoA节点。
A. 算法和策略 现在,我们的目的是在这个二方图上进行社区检测, 并将所有的EoA节点归入群组。在本小节中,我们采用 Community detection from low-rank excitations of a graph filter 中的低等级社区检测算法,对双联图中的EoA节 点进行聚类。文献中的低等级社区检测算法来对双子图中的EoA节点进行聚类。这个想法是假设所有的EoA节点 形成一个低等级的社会子图,其中一些领先的EoA节点 将决定其他节点对CA节点的关注。本着这种精神,我们 将二方图的EoA节点集划分为具有高边缘密度的子集。 这可以通过在EoA节点观察到的图信号的低等级输出协 方差马三上应用聚类算法来实现。为了进行 它,我们把这个社区检测问题看作是一个GSP问题,其 中图 是在EoA主导节点(见图)且其将通过一个过滤器 $$ H(S) = \sum_{l=0}{L-1}h_lSl=V(\sum_{l=0}{L-1}h_l)Λl)V^H$$
其中,S是图的拉普拉斯矩阵,L是滤波器的度数,R是主导节点的数量。滤波器,R是主导节点的数量。输出信号 x∈R N被定义在所有的EoA节点上,它的生成方式是
在此,V和Λ来自SVD分解的S。上述公式意味着,在我们的图模型中,EoA领导节点的意见 的意见决定了所有节点的状态。基于 上述模型,在所有EoA节点观察到的图信号 可以表示为
DL
PD-SECR
基于PD-SECR的以太坊庞氏骗局检测
Ethereum Ponzi Scheme Detection Based on PD-SECR
https://doi.org/10.1155/2022/2316310
庞氏骗局的几个特点。
(i) 在项目网站上对区块链的功能有轰炸式的描述(如果有的话)。利用高回报无风险的虚假广告来吸引投资者,而不提供重要信息,如项目运营商。
(ii) 投资者的回报主要由新投资者投入的资本来支持,没有真正的项目技术支持。
(iii) 以太坊合约代码包含一个层次结构,即新投资者向早期投资者支付费用的回报机制。(击鼓传花
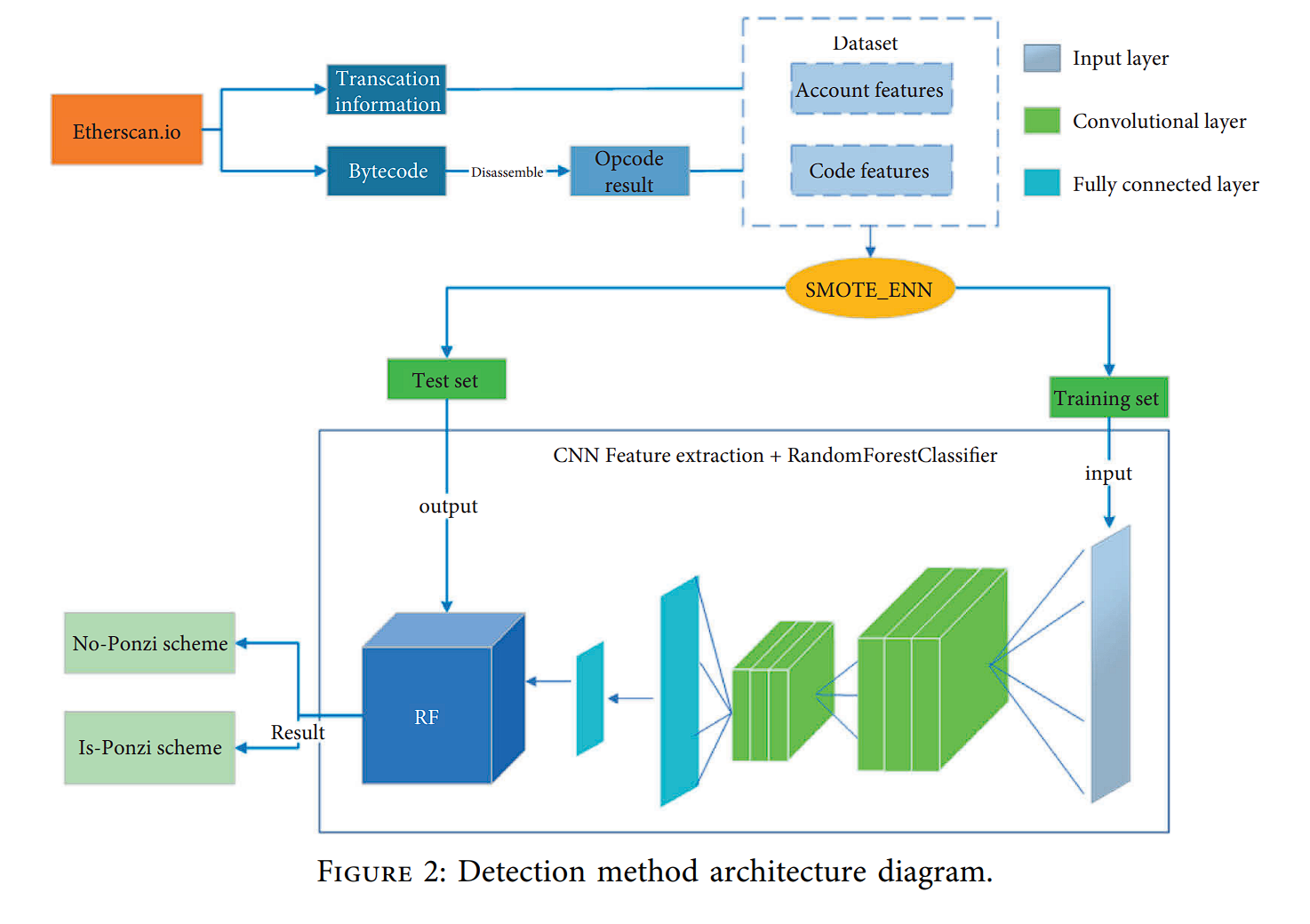
PD-SECR (CNN-RF联合检测方法:融合不平衡数据和预处理算法)
卷积神经网络和随机森林模型的有效融合 CNN_RF Fusion
从Ethereum.io获得交易信息和合约编译的字节码
通过相关计算,从交易信息中提取相应的特征。
使用反编译器将字节码分解为操作码(opcode),并通过计算操作代码的调用频率建立代码特征。
由于样本数据的严重不平衡,为了解决这个问题,引入了 SMTOE_ENN数据不平衡处理算法。
SMOTE_ENN不仅可以处理数据不平衡问题,而且可以避免数据的重复性。
然后将处理后的数据按 4:1 的比例分为训练集和测试集。
首先,构建了一个由三个卷积层和两个全连接层组成的CNN特征提取模型,从数据集中提取关键数据特征。
CNN提取的数据特征输入到RF模型,用于训练分类模型。
训练完成后,测试集评估模型的性能。
Precision、Recall和F1 score评估模型。



特征选择
研究选择了16个特征,其中包括9个操作码特征和7个账户特征,这些特征有利于庞氏骗局的合同识别。
opcode features
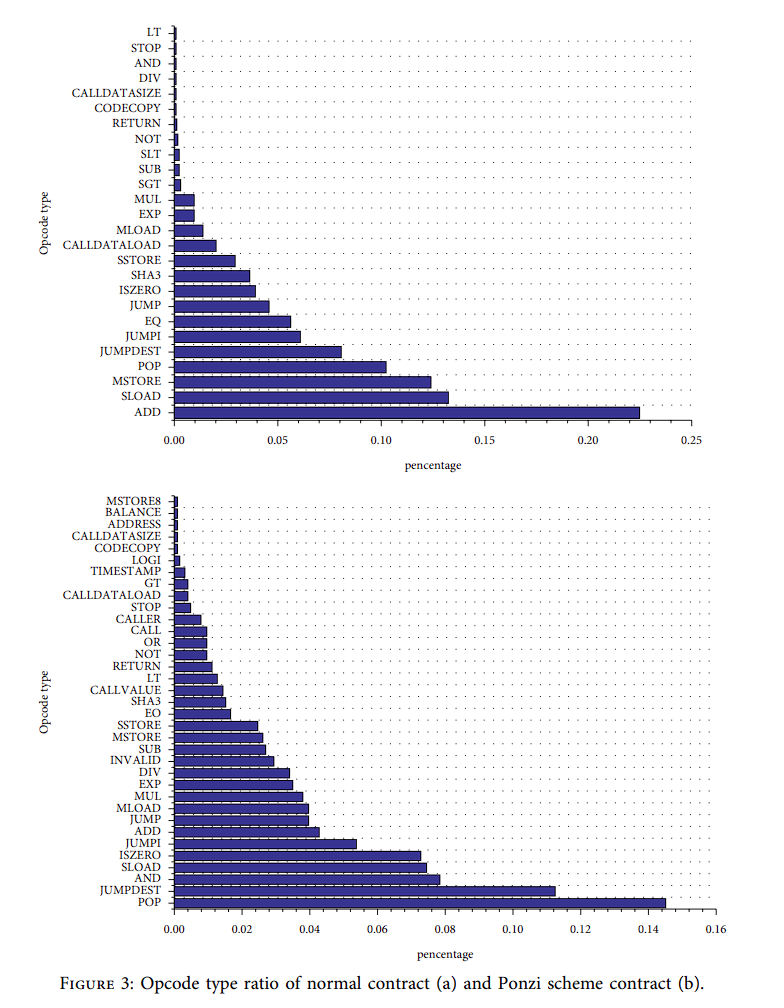
如果满足默认的执行条件,一个以太坊智能合约可以被强制执行。因此,在庞氏骗局合约的代码结构中,往往包含了一个欺诈机制。操作码也表征了合约的基本问题。
为了有效区分现实世界中的庞氏骗局合同和正常合同,本文分析了合同操作代码的类型和频率,并从合同代码中提取特征。本文将智能合约中不同操作码出现的频率计为操作码特征。
如图3所示,在不考虑 PUSH、DUP和SWAP等出现频率最高的操作码的情况 下,庞氏骗局智能合约与正常合约操作码之间存在着明显的差异。
最关键的区别:庞氏骗局合约比正常合约包含更多的威胁性功能代码(如CALLER、EXP等)。
account features
以太坊上的庞氏骗局合约与普通合约相比,在账户交易特征上有一些不同之处。特别是,在合约交易中,以太币的流通过程有明显的差异。
通过人工验证,账户特征可以总结为以下几点:
- 只有少数早期合约参与者获得了高比例的回报,几乎所有的回报都集中在前两个合约参与者。具体来说,智能合约的创建者获得的回报最高。
- 在许多庞氏骗局的智能合约中保持低余额与正常的智能合约相比,一般采取快速分配投资所得的操作
以太坊账户分为外部和内部账户(地址);例如,当用户创建一个地址时,它被称为外部地址,因为它是用来从外部访问区块链的。
当我们在以太坊上部署一个智能合约时,我们会生成一个内部地址,作为运行的区块链程序(部署的智能合约)的指针。
我们可以在外部将其定位为一个要调用的功能,或在内部,使另一个部署的合同可以在部署的合同上调用该功能。
因此,我们从外部和内部账户交易中提取七个代表性特征,作为识别庞氏骗局合约的另一种方式。
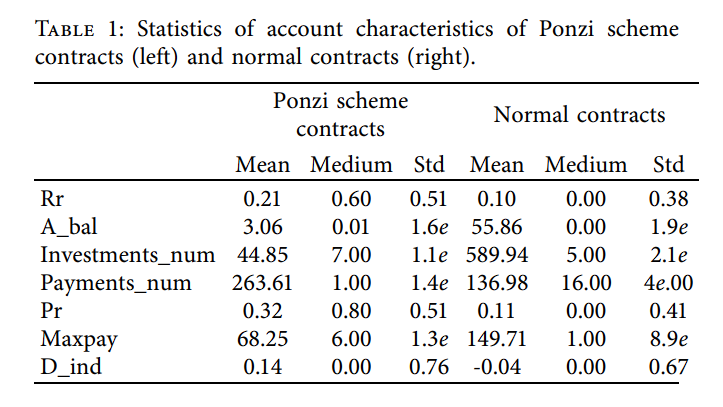
| Column | Description |
|---|---|
| Rr | 合约付款前已投资的收款人百分比 |
| A_bal | 合约余额 |
| Investments_num | 每份合同收到的投资数量。 |
| Payments_num | 每份合约的交易支出数。 |
| Pr | 至少收到一笔款项的投资者百分比 |
| Maxpay | 一个合同账户支付给同一个收款人账户的最大交易数量 |
| D_ind | 合约中所有参与者支付和投资之间的量化差异。 |
GNN
- GNN数据内容全在transaction,无transfer
EH-GCN
Ethereum Account Classification Based on Graph Convolutional Network
利用图卷积网络(GCN)来解决以太坊中的账户分类问题:
- 将以太坊交易记录建模为一个大型交易网络,发现该网络具有高异质性,其中具有不同特征和不同标签的帐户相互连接。
- 提出了一种基于GCN的模型,称为EH-GCN,证明实现了最先进的分类性能
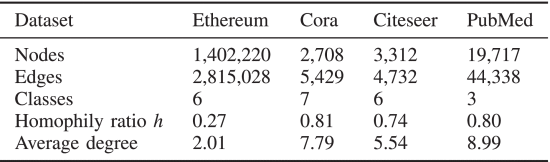
同质比表示连接相同Node的edge的百分比。可以观察到,与这三个基准相比,以太坊交易网络非常大且稀疏。
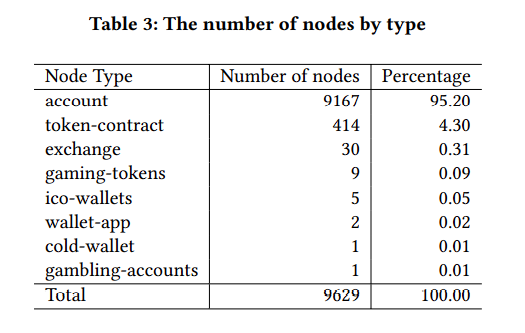
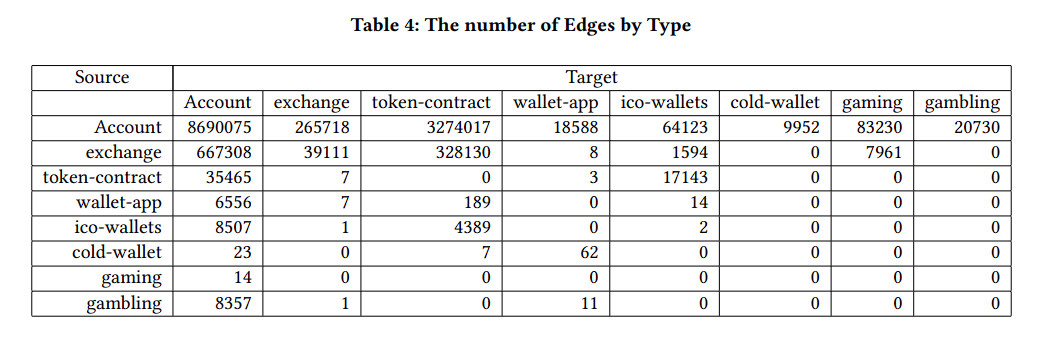
数据来源
从Etherscan获得816个带有真实标签的帐户,这些账户参与六个不同的业务。收集其与Etherscan提供的API的1级和2级交易关系。最后,将剩余的交易关系和涉及的账户抽象为具有140万个节点和281万条边的事务网络。
(从816只靠1、2级就带出了140w和281w,肯定是挖到Exchange和Mining老家了

从交易记录中提取:12个节点特征(例如,余额,交易金额,交易频率等)。
训练/验证/测试拆分为7/1/2
方法设计
抽样策略
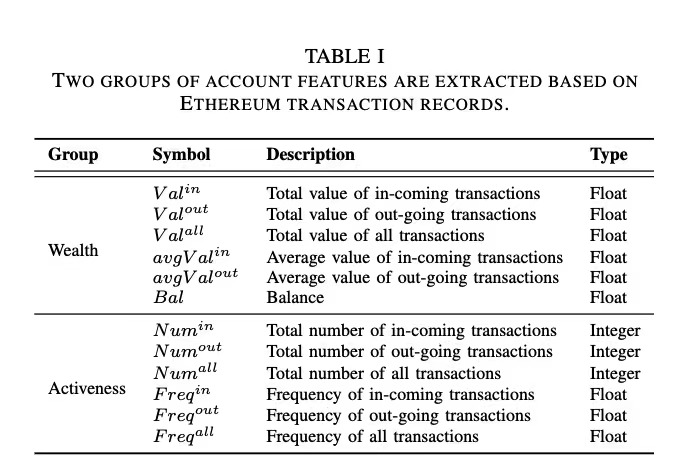
基于网络的采样策略如图1(a)所示
在采样策略中,考虑了三角形graphlet结构和度来搜索高阶节点,以保持与目标节点的相关性。
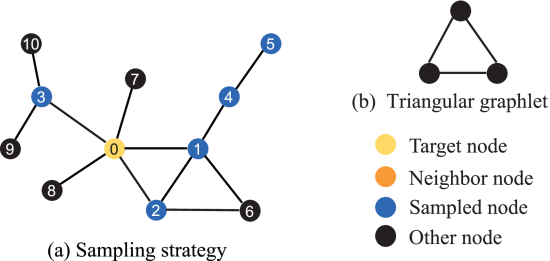
Graphlets是复杂网络的小型连接诱导子图,已被广泛认为是从微观角度分析节点之间关系的工具。我们使用的三角形图显示了三个节点之间的紧密关系。
我们推导三角形图形集TG 和关系集GL(v)和NG(v)节点数v 在图表上:
GL(v) 是一组出现在三角形图形中的节点,NG(v,u)是一组出现在有v和u的三角形graphlet中的节点。
给定一个目标节点v,在采样过程开始时,候选节点集C(v)被初始化为一个包含v的一阶邻居的集合。为了在一个具有异质性的大规模网络中获得采样节点集S(v),我们首先考虑每个目标节点的小图,这有助于保持其相关性。我们将GL(v)初始化为所有与目标节点v有三角形小图的节点。
为了在抽样程序中保留更多的结构信息,我们使用X(v)来维护小图中出现的候选节点的集合,将X(v)设置为GL(v)∩C(v)。如果X(v)不是空的,我们就用基于小图的概率质量函数从其中抽取一个新节点u。
degree(⋅) 返回输入节点的度。-> 具有较高程度中心性的节点往往对其他节点有更大的影响。
之后,C(v)将通过添加u的一级邻居(S(v)中的节点除外)进行扩展,以便下一次采样。通过重复上述过程M次,可以得到一个抽样的节点集S(v)。这里M表示每个目标节点的抽样节点数,是所提方法的一个超参数。
这种抽样策略可以利用网络结构,收集更多有价值的节点。
Mix-Grained Aggregators 混合粒度聚合器
为了聚合来自高阶邻域的信息:可以以细粒度的方式聚合一阶邻域信息,并以粗粒度的方式收集高阶信息。
- Fine-grained aggregator 细粒度聚合器: 细粒度聚合器用于收集目标节点的所有一阶邻居的信息。
- Coarse-grained aggregator 粗粒度聚合器: 这个聚合器将只集中在已采样的节点上,以减少计算和时间的复杂性。
一阶和高阶嵌入的组合
由细粒度和粗粒度聚合器分别得到的一阶和高阶嵌入可以收集不同位置的信息,并且很可能是不一样的。因此,为了明确捕捉节点表示中的局部和全局信息,我们建议在最后一层结合每个节点的中间嵌入。
l是模型的层级,是节点v的最终表示。在实现中,我们使用连接法来捕捉局部和全局信息。
EH-GCN
接下来,将描述如何在上述三个关键设计的基础上建立起建议的模型。
- 模型的第一层通过使用细粒度的聚合器来聚合所有的一阶信息:
其中 是节点v的给定输入特征。
此外,使用抽样策略得到高阶节点,并使用粗粒度聚合器在第二层聚合高阶信息,其结果显示为:
值得注意的是,S(v)中的高阶节点可以在第二层被聚合。在最极端的情况下,M阶邻居可以被聚集起来。
最后,我们在网络的最后一层结合一阶嵌入和高阶嵌入。
实验结果
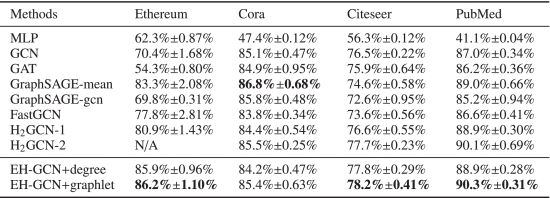
模型在以太坊数据集上的出色结果可能要归功于采样策略和混合粒度聚合器,它们聚合了EH-GCN模型中只有两层的高阶邻居。
相反,GCN和GAT在以太坊中的准确性相当低,GAT的准确性甚至低于MLP。这种现象也可以归咎于与目标节点非常不同的低阶邻居的噪声。
此外,在以太坊中,具有邻域采样机制的两种方法,即GraphSAGE和FastGCN,可以达到比GCN更高的精度,这进一步证明聚合一些低阶邻居甚至对异质设置下的性能产生负面影响。
H2GCN是最近为异质网络设计的方法,还收集高阶邻域信息。H2GCN-1可以在以太坊数据集中实现相对较高的精度,但会出现“内存不足”问题。(聚合所有单跳和双跳节点并保留所有中间嵌入)
为了评价所提出模型在同亲性设置下的泛化能力,在均质比相对较大的基准上进行了实验。如表III所示,Cora、Citeseer和PubMed的结果表明,所提出的方法在同亲条件下具有竞争性。这应该主要归功于我们的细粒度和粗粒度聚合器,它们在采样中选择更有价值的相邻节点。
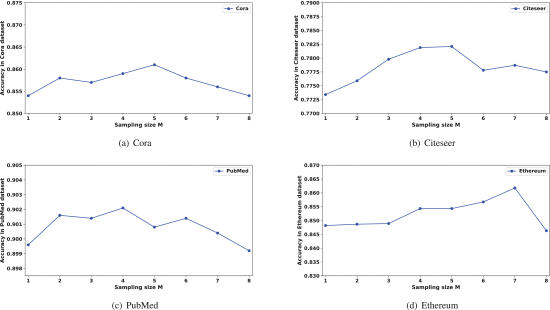
在采样策略中采样大小M 在 EH-GCN 中的影响:可以看出,EH-GCN在以下情况下获得最佳结果:M 为 5、5、4 和 7。
随着抽样规模的增加,总体准确率首先增加,然后下降。这表明,当M相对较低时,模型不能从高阶邻域提取足够的信息,因此准确率随着M的增加而增加。而当邻域信息充足时,信息冗余导致精度随着M的增加而降低。
FA-GNN
FA-GNN: Filter and Augment Graph Neural Networks for Account Classification in Ethereum


数据重用了
目标:通过开发一个 GCN 模型对图中的每个节点进行分类
架构
FA-GNN 的框架如图所示,它包含三个主要组成部分,包括邻居过滤,特征增强和网络嵌入。
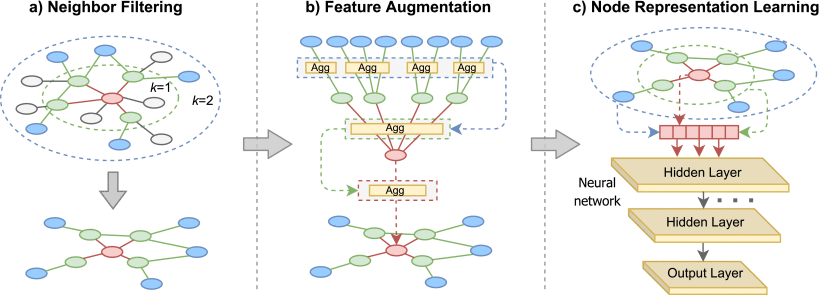
- Neighbor Filtering 邻居过滤: 在事务网络中,一对连接节点之间的关系与事务量等事务特征和程度等网络特征有关。为了去除邻居带来的冗余信息,我们设计了这个组件,并通过不同的偏好策略滤除一定比例的邻居。
- Feature Augmentation 特征增强: 针对网络嵌入学习过程中的高阶信息,提出一种特征增强组件,通过聚合高阶信息为每个节点生成增强特征。
- Node Representation Learning 节点表示学习: 以增广的节点特征为输入,节点表示学习组件通过两层神经网络为网络中的每个节点学习一个低维表示向量。然后,将得到的表示向量作为下游以太网事务网络分析任务的输入。
Neighbor Filtering
与传统的网络数据(如 Cora)相比,以太网交易网络中的连接节点之间在节点特征方面存在显著差异。这是因为以太网事务网络中的节点倾向于与其他类中的节点交互。
该方法不使用完全邻居集合的信息,而是通过邻居滤波后得到的邻居集合中每个节点的邻居搜索,通过探索邻居节点的重要性来识别更有效的邻居信息。
帐户分类结果 (RQ1)
我们首先比较了 FA-GNN 和基线方法在以太帐户分类任务中的性能。由于邻域保持率 λ、深度 k 和邻域滤波偏好 p 是可调参数,本文以Macro F1为主要度量,通过对 λ ∈{0.1,0.2,… ,0.9} ,k ∈{1,2,… ,10}和 p ∈{1,2,3}进行网格搜索,得到了在最佳参数下的平均结果。从表 VI 和表 VII 所显示的结果可以明显看出,在不同的数据集分割中,所提出的 FA-GNN 优于基线方法。具体而言,在分割1中,我们比基线方法获得的最高Macro F1评分获得8.93% 的增益,交易量为优先级(p = 1) ,邻居保留率 λ = 0.2,聚集深度 k = 4。在分割2中,以交易时间为优先级(p = 2) ,邻居保留率 λ = 0.1,聚集深度 k = 6,我们比基线的最佳Macro F1评分获得7.82% 的增益。在分割3中,通过聚合最高度(p = 3,λ = 0.1,k = 1)的前10% 单跳邻居的信息,我们获得了最佳性能,比基线方法获得的最佳Marco F1评分提供了1.53% 的增益。
敏感度分析 λ & k (RQ2)
过滤偏好的评估 (RQ3)
合并策略的评估 (RQ4)
Ablation Study 消融研究 (RQ5)
Heterogeneous
Ethereum Fraud Detection with Heterogeneous Graph Neural Networks
文本
白皮书+GNN
北航博士发在Journal of Parallel and Distributed Computing
对白皮书的分析是全面评价区块链产品的重要途径
目的是探索一种更有效的方法,用于白皮书中复杂信息的特征提取,并将其用于文本分类和聚类。
- 提出了一个新颖的区块链白皮书自动分析框架
- 介绍了区块链产品的多类要素
- 为白皮书设计了一个元架构
- 定义了一个基于元路径实例的白皮书之间的相似度测量
- 探讨了基于GCN和GAT的异质图神经网络(GNN)
- 利用异质图网络生成白皮书的聚合嵌入,并将学到的白皮书特征应用于聚类和分类任务
本文使用异质图神经网络(Heterogeneous GNN)来分析区块链白皮书。
首先,第3.1节使用NLP工具提取实体和关系,
并在第3.2节中使用它们来构建HIN。
然后,在第3.3节中,人们可以根据HIN中的元实例和定义的相似性指标得到加权相邻矩阵,并利用Doc2vec技术 学习文本特征。
最后我们可以让流行的图神经网络,包括图卷积网络 和 图注意力网络,将结构信息和节点特征都整合到白皮书嵌入中。
NLP

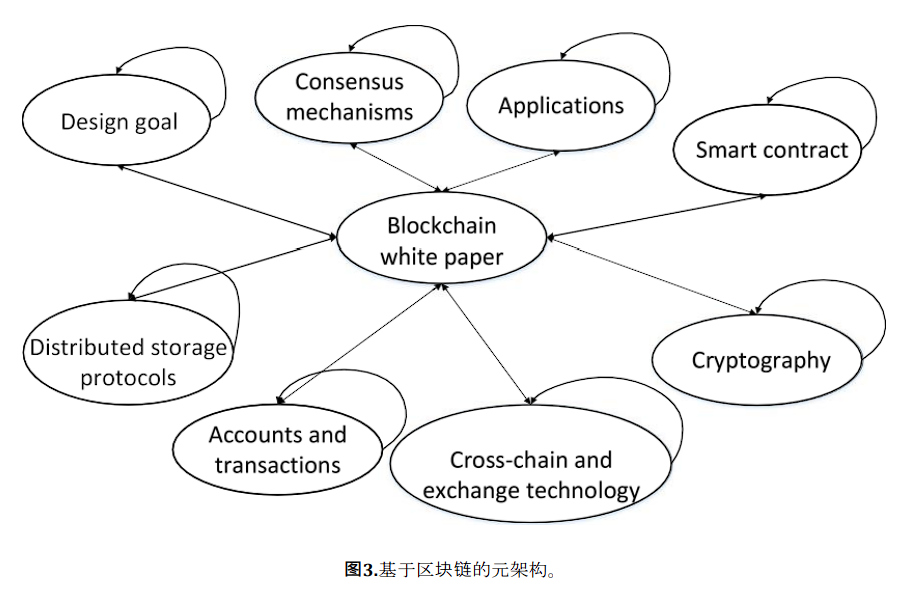
区块链白皮书是一份产品描述文件,介绍项目的技术框架、商业模式和发展前景。一般包括产品的主要功能和性能,以及涉及的核心技术特点和优势,还有行业内的应用案例。
与传统的文本挖掘技术不同,区块链产品白皮书涵盖了特定的主题和实体。例如,区块链技术由共识机制、账户和交易行为、智能合约、密码学、分布式存储协议、跨链和交换、经济和激励、和治理技术等组成。
图中这些元素之间有各种关系,其中包括共识机制、跨链和交换技术、密码器、智能合约之间的关系。
HIN
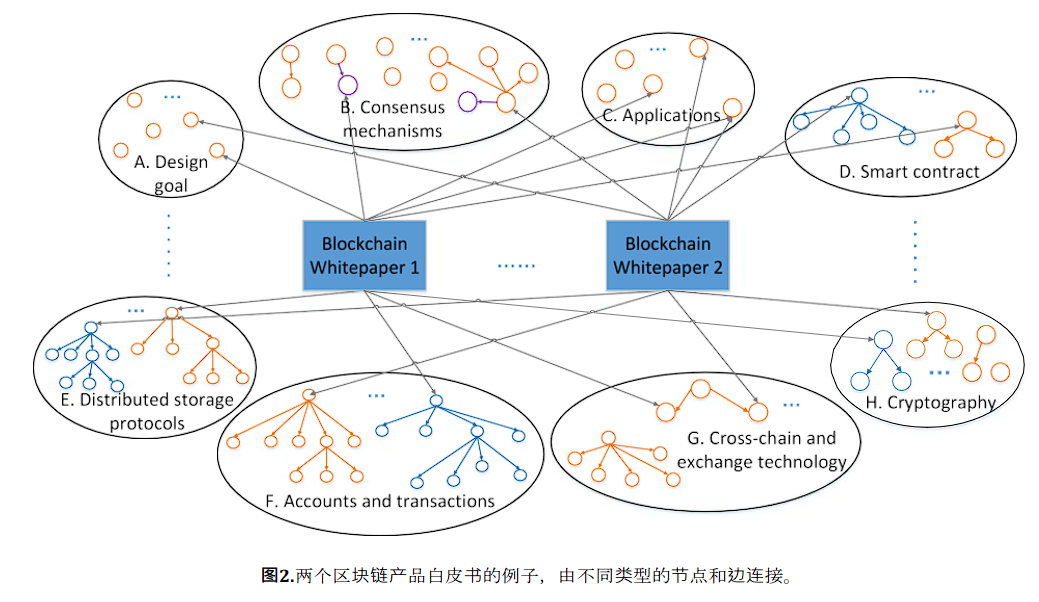
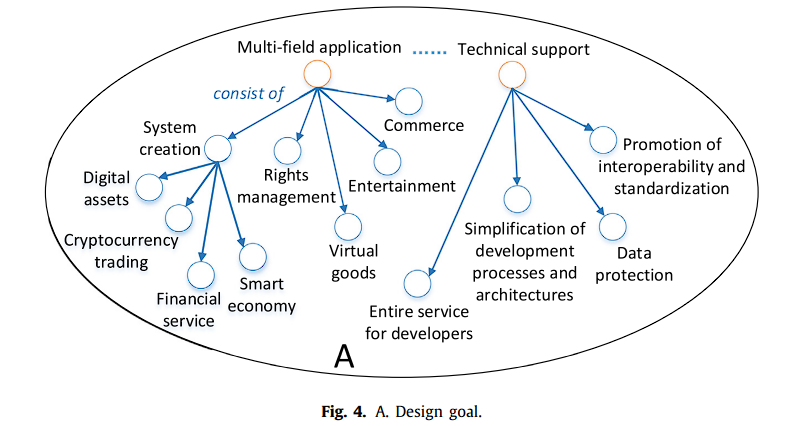
A. 设计目标:白皮书的设计目标是提供多领域的应用和技术支持(图4)。
前者主要涵盖金融产品体系的创建(数字资产、加密货币交易、金融服务、智能经济)、权利管理、虚拟物品娱乐、商业等领域。
后者包括为开发者提供整体服务,简化开发流程和架构,数据保护和促进互操作性和标准化。
区块链白皮书的一般类型包括基本链、加密货币、智能合约、应用或服务平台和共识算法。
详细来说,这些白皮书涉及项目设计目标、共识机制、智能合约、密码学、账户和交易、经济模式和激励措施以及应用。
以下是关键点的细节。
B. 共识机制
C. 应用
D. 智能合约
白皮书涉及三种类型的智能合约系统:
- 原始智能合约(Viacoin, Stellar, Verge, Zcash, Nuls),
- 基于比特币协议的智能合约(Komodo)
- 基于以太坊的智能合约 ( Iconomi, Golem, FunFair, Status, Smart- Cash, Decentraland, MOAC)。
E. 分布式存储协议
F. 账户和交易
G. 跨链和交换技术
H. 加密算法
相似性

Oi, Oj = 俩白皮书
Pk = 一组元路径
Path_Count_p 计算俩白皮书之间元路径实例数
形成 (Blockchain whitepaper) – [Element] – (Blockchain whitepaper) 图 -> 邻接矩阵
GNN
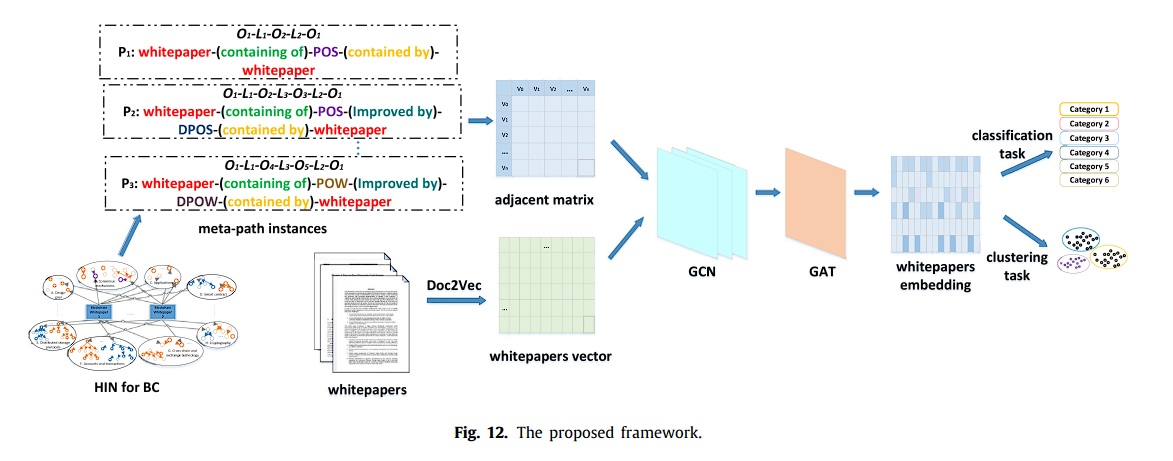
采用Hold-Out法和10倍交叉验证法分别得到模型的输出结果
数据

结果
分类
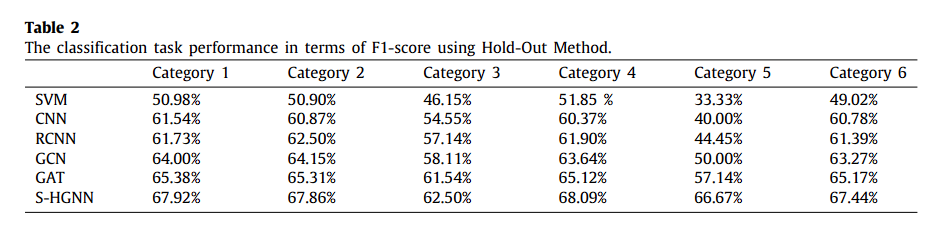
使用Hold-Out方法的分类任务性能在F1分数方面的表现。

使用10倍交叉验证的分类任务F1分数

使用Hold-Out方法在Micro-F1和Macro-F1方面的分类任务表现

使用10倍交叉验证的Micro-F1和Macro-F1的分类任务性能
聚类
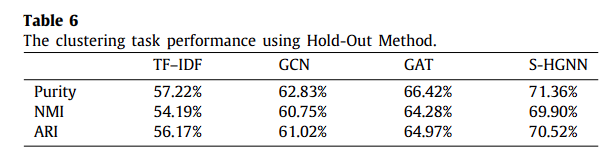
使用Hold-Out方法的聚类任务表现。
?
Token的异常交易检测
现在的特征->账户eth余额====>token balance!
数据流
flowchart LR
A[Mongodb] -->|Cypher| B(Neo4J)
B -->|graphml| C{networkx}
C -->|utils.convert.from_networkx| D[PyG]
C -->|load| E[Gephi]
异常检测:BitGCN
DeFi
基于特征融合和正未标记学习的以太网套利检测
实验数据:
以太坊交易记录在基础区块链中,可以从 Ethereum 客户端检索到。为了建立套利检测模型,需要采集具有套利者角色的地址数据集。Bloxy是一个提供区块链实时数据分析的网站。在 Bloxy,我们收集包含套利地址的标记地址的数据集,并将这些数据作为基本事实进行清理。我们利用经济学领域论文和相关新闻报道提供的数据集来验证 Bloxy 提供的数据集的准确性。在数据清理过程中,我们获得了1,280个标记的套利地址和63,038个与套利相关的交易记录。一般来说,这些标记的地址包括 DEX (例如 UniSwap2和 SushiSwap3)和 CEX (例如 Binance4和 Huobi5)。我们认为,我们收集的数据集是合理和有代表性的,因为我们标记的交易所恰好包括顶级交易所,如 UniSwap 和 Binance,根据 Coinmarket cap 的统计数据
-> Bloxy停止注册,得用bitquery
衡量 DeFi 中的非法活动:以太坊案例
Measuring Illicit Activity in DeFi: The Case of Ethereum
作者

2021年09月 International Conference on Financial Cryptography and Data Security
摘要:文章分析了以太生态系统中非法活动的规模。使用来自Blockchain Intelligence Group(BIG)的专有标签数据,我们调查了一些“恶意”以太地址的特征。我们首先计算涉及这些地址的交易总数以及通过它们转移的资金总额,然后描述恶意地址交互的 ERC-20令牌或 DeFi 应用程序的智能合同地址。最后,我们应用机器学习技术来识别额外的“恶意”地址,通过从与最初的一组恶意地址的事务关系中对所有以太网地址进行网络聚类分析。
-> 感觉就是个启发式聚类没DeFi
简介
尽管[4]对比特币的非法活动状况进行了有趣的分析,但其他加密货币领域,尤其是建立在智能合同基础上的新兴 DeFi 领域,以及它们对非法活动的潜在用途,仍未得到探索。为了弥补这一差距,我们正在寻找其他加密货币和 DeFi 系统。
因此,我们的研究侧重于以下问题:
比特币以外的加密货币以及智能合同应用程序中存在的非法活动达到了何种程度?
在这项工作中,我们首先调查以太坊(第二大加密货币,截至2021年1月市值超过1200亿美元)。考虑到以太坊的丰富特性(它配备了智能合同功能,而不是比特币) ,我们希望探索在该系统上进行的非法活动,也看看智能合同和 ERC-20令牌的特殊情况。
方法论
为了量化以太坊上的非法活动,我们使用BIG提供给我们的一组标记为“恶意”的初始以太坊地址集来识别一组地址/交易,我们称之为我们的原始恶意集(MS)。然后,我们通过下面解释的网络聚类分析,分析这个集合如何与所有以太网地址的其余部分相互作用。
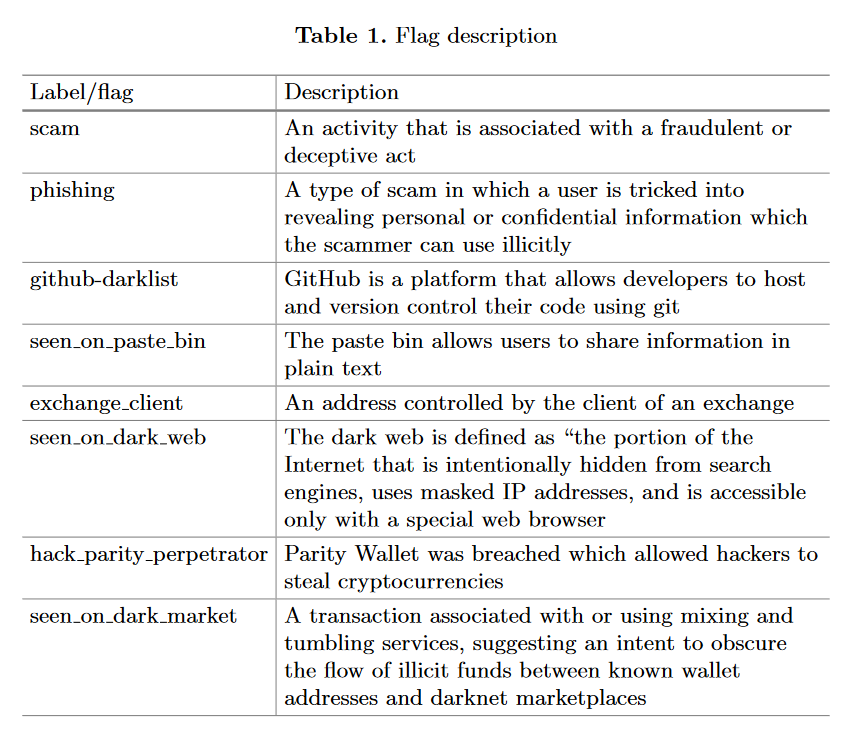
由于来自 BIG 的原始数据包含所有地址的详细标签标志,为了确定 MS,我们需要问什么类型的标签描述非法活动?通过与 BIG 的合作,并基于以前的工作(Sex, drugs, and bitcoin: how much illegal activity is financed through cryptocurrencies?) ,我们专注于许多涉及诈骗、钓鱼攻击和暗网交易的标志。表1提供了这些标签的详细描述。
我们总共获得3559个地址标记为恶意下的旗帜说明给出了上述。在这3559个地址中,只有2628个出现在以太区块链中。剩下的是已知的恶意地址,但是没有任何资金转移到这些地址。例如,一个地址可能已经张贴在一个已知的骗局,但没有资金被转移到它,所以它不会实际上出现在区块链。
鉴于上面描述的恶意地址集合,我们通过2015年7月至2020年12月期间的整个以太坊区块链数据库来分析非法行为。具体来说,我们研究了世界协调时2020年5月26日星期二16:23:22之间以太区块链中的区块。数据库中的第一块是在世界协调时2015年7月30日星期四15:26:13开采的。
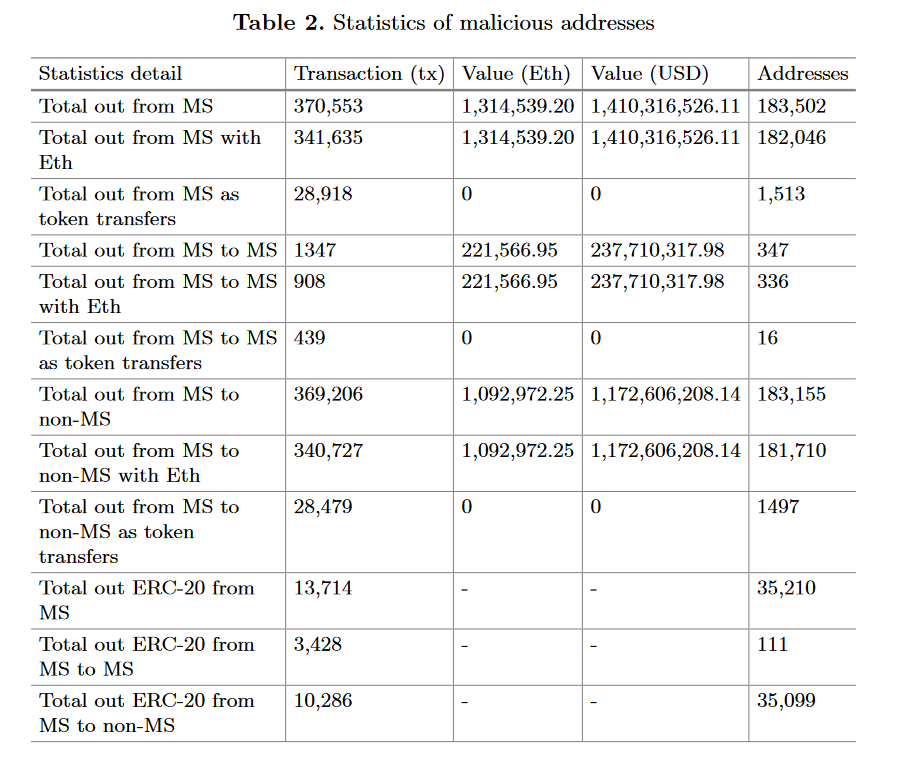
截至2020年12月,恶意设置(MS)目前拥有326,443.71 Eth。表2列出了一些汇总统计数据。第一行计算(a)恶意集合(MS)完成了多少事务,(b)这些事务的总价值是多少(以太和美元计算——使用2021年1月13日的转换率) ,以及©接收地址的总数(即恶意集合与多少个地址交互)。由于某些以太粒子事务是“常规”事务,即只使用以太粒子,而其他事务是令牌传输或更一般的触发智能合同状态更新的事务,第2行和第3行分别查看源自恶意集(MS)和令牌传输的“常规”事务。第4-6行侧重于恶意集合中的事务(即发送和接收地址都在 MS 中) ,第7-9行是互补集合,即从 MS 到非 MS 地址的事务。最后,第10-12行查看恶意集中 ERC-20事务的数量。
健壮性: 扩展恶意集
除了分析 MS,我们还进一步进行了网络聚类分析,以确定是否应该将额外的以太网地址标记为恶意地址。接下来我们进一步利用以太坊的交易网络来识别潜在的恶意用户。基本假设如下:
*如果已知一组 S 用户参与了 BIG 提供的非法活动,那么完全或主要与 S 用户进行交易的用户 X 也可能参与了非法活动。类似地,主要与不在 S 中的用户进行交易的用户 Y 可能是一个顺从的用户。*这种直觉驱使用户根据其交易伙伴将其分类为合规和非法。
更正式地说,我们应用的方法是一种网络数据聚类算法,它将用户集(网络术语中的“节点”)和用户之间的交易(网络术语中的“边”或“链接”)作为输入。该算法的输出是将用户分配给组,从而使组的“模块化”(组内链接的密度和组间链接的稀疏性)最大化。如果用户不成比例的交易份额与非法(合规)组的成员有关,则该方法将用户标记为非法(合规)。这种方法并不假定用户只从事顺从或非法活动ーー用户可以同时从事这两种活动。因此,合规团体和非法团体之间会有一些交易。
我们应用与(Sex, drugs, and bitcoin: how much illegal activity is financed through cryptocurrencies?)中相同的方法: 由(A smart local moving algorithm for large-scale modularity-based community detection)开发的智能局部移动(SLM)算法的一个变体,适用于我们的具体应用。该算法的名称(“smart moving”)来自于这样一个事实,即如果这种移动改善了模型拟合,则该算法通过将节点从一个节点移动到另一个节点来找到网络中的底层组结构。应用于我们的数据,算法如下:
- 步骤1: 将所有标记的非法用户分配给非法组,将所有剩余用户分配给符合要求的组。
- 步骤2: 循环遍历每个用户,对每个用户执行以下操作:
- 如果用户与该用户当前分配的组的成员进行不成比例的事务处理,则将该用户保留在该组中;
- 否则,将用户移动到另一个组(如果用户被分配到非法组,则将用户移动到符合要求的组,反之亦然)。
- 步骤3: 重复步骤2,直到在一个完整的循环中通过所有用户,没有用户在组之间切换。此时,对组的分配是稳定的,并确保每个成员与同一组的其他成员不成比例地进行贸易。
由于算法的迭代性质,并非所有“标记”的非法用户都必然留在非法组中。例如,有可能一些用户已经被 BIG 标记,但主要是为了兼容目的而使用ether。这将被步骤2中的算法识别,并且用户将被移动到符合要求的组中。
在扩展算法之后产生的恶意集合是23,638个地址,并在2次迭代之后收敛。一个有趣的发现是,尽管恶意集增加了很多,但是传出事务中的 ETH 总量只有轻微增加,达到1,316,153.44 ETH。
结论
本文的目的是引发一些讨论,什么是非法活动量化的以太和其他 DeFi 系统,我们如何可能检测和分析它。我们介绍了我们对 Ethereum 的最初调查结果,并讨论了我们的观察结果。